
In software development, some bugs are mere annoyances—a light drizzle on an otherwise sunny day. Others, however, are catastrophic. They are the digital equivalent of a Category 5 hurricane, a swirling vortex of chaos that rips through production environments, corrupts data, and brings systems to a grinding halt. Seen from a distance—the “space” of high-level monitoring dashboards—these bugs appear as a massive, incomprehensible storm. They are characterized by vague error messages, non-reproducible behavior, and a blast radius that affects multiple, seemingly unrelated parts of the system. This is the ultimate challenge in software debugging: taming the hurricane.
Tackling such a monumental bug requires more than just a few `console.log` statements. It demands a systematic, multi-faceted approach that combines high-level observation with deep, granular inspection. It requires mastering a diverse set of debugging techniques and wielding powerful debug tools with precision. This guide will take you from the satellite view down into the eye of the storm, exploring the strategies needed for effective full stack debugging—from frontend debugging in the browser to complex backend debugging in microservices architectures. We will cover everything from foundational principles to advanced practices in JavaScript debugging, Node.js debugging, and Python debugging, equipping you with the knowledge to navigate and dismantle even the most formidable software hurricanes.
The Anatomy of a “Hurricane” Bug: Identifying a Cat 5 Problem
Not all bugs are created equal. A “Category 5” bug is defined by its complexity, impact, and elusiveness. Understanding its characteristics is the first step toward effective bug fixing. These issues often stem from the intricate interplay of modern software architecture, including distributed systems, asynchronous operations, and complex state management.
Characteristics of a High-Impact Bug
- Intermittent and Non-Reproducible: The most frustrating trait. The bug appears under specific, unknown conditions—perhaps related to server load, network latency, or a rare race condition in async debugging. Trying to reproduce it in a controlled development environment often fails, making traditional code debugging methods ineffective.
- Vague or Misleading Error Messages: Instead of a clear “Null Pointer Exception,” you might get a generic “502 Bad Gateway” or a cryptic timeout error. The initial error messages and stack traces point to a symptom, not the root cause, sending developers on a wild goose chase through the wrong service or code path.
- Complex Dependencies (Microservices Debugging): In a microservices architecture, a single user request can trigger a cascade of calls across dozens of services. A failure in one downstream service can manifest as an error in a completely different, upstream service. Tracing the origin becomes a significant challenge in system debugging and API debugging.
- Production-Only Manifestation: The bug only appears under the unique conditions of the production environment—the specific data, user traffic patterns, or infrastructure configuration. This makes production debugging a critical, yet delicate, process.
- State Corruption: The most insidious bugs don’t cause an immediate crash. Instead, they silently corrupt data or application state over time, leading to a massive, delayed failure whose origins are buried deep in past transactions. This often requires advanced memory debugging to uncover.
The View from Space: Foundational Monitoring and Logging
Before diving deep, you need a high-level view of the storm. This “satellite” perspective is achieved through robust logging, monitoring, and error tracking. These tools provide the context needed to understand the bug’s blast radius and identify patterns in its behavior. This is a core tenet of debugging best practices.
Strategic Logging and Debugging
Effective logging and debugging is more than just scattering print statements. It’s about creating a structured, searchable narrative of your application’s execution. Logs should include:
- Timestamps: To correlate events across different services.
- Correlation IDs: A unique ID assigned to each incoming request that is passed through every service it touches. This allows you to trace a single user’s journey through a complex system.
- Log Levels: Use levels like DEBUG, INFO, WARN, ERROR, and FATAL to filter noise and focus on critical events.
- Structured Data (JSON): Logging in a structured format like JSON makes logs machine-readable, allowing for powerful querying and analysis in tools like Elasticsearch or Splunk.
Comprehensive Error Tracking
While logs record what you tell them to, error tracking platforms (like Sentry, Bugsnag, or Rollbar) automatically capture unhandled exceptions in your application. They provide aggregated views of errors, including full stack traces, browser/OS context, and the frequency of occurrence. This is invaluable for identifying the most impactful JavaScript errors or Node.js errors affecting your users. Effective error monitoring helps prioritize which storms to tackle first.

Mastering Browser Debugging with Chrome DevTools
For frontend debugging and web debugging, browser developer tools are indispensable. Chrome DevTools is a powerhouse for diagnosing issues on the client side.
- The Console: The debug console is more than `console.log()`. Use `console.table()` to display arrays of objects in a clean, tabular format, `console.warn()` and `console.error()` to differentiate output, and `console.group()` to organize related log messages.
- The Network Tab: Essential for network debugging and API debugging. You can inspect every HTTP request, view headers, analyze payloads, and check response times. Filter requests to isolate the problematic API call and check for status codes like 4xx or 5xx.
- The Performance Tab: For tackling performance bottlenecks, this tool helps you record and analyze runtime performance. It’s a key part of debug performance, helping you find slow functions or rendering issues in React debugging or Vue debugging.
Entering the Eye of the Storm: Interactive and Advanced Debugging Techniques
Once high-level monitoring has helped you pinpoint the general area of the problem, it’s time to move in for a closer look. Interactive debugging allows you to pause your code’s execution, inspect its state at a specific moment, and understand its logic flow step-by-step.
The Power of Breakpoints
A breakpoint is a deliberate stopping or pausing place in a script. It’s the most powerful tool for code debugging. Instead of guessing a variable’s value with a log statement, you can pause the code and inspect everything in scope.
- Conditional Breakpoints: Don’t want to stop on every loop iteration? Set a conditional breakpoint that only pauses execution when a specific condition is met (e.g., `i > 1000` or `user.id === ‘problem-user-id’`).
- Logpoints: A variant of a breakpoint that logs a message to the console without pausing execution. This is a fantastic way to inject logging into your code directly from the debugger without modifying the source files.
- Exception Breakpoints: Configure the debugger to automatically pause whenever an unhandled (or even a handled) exception is thrown. This takes you directly to the source of the error when it occurs.
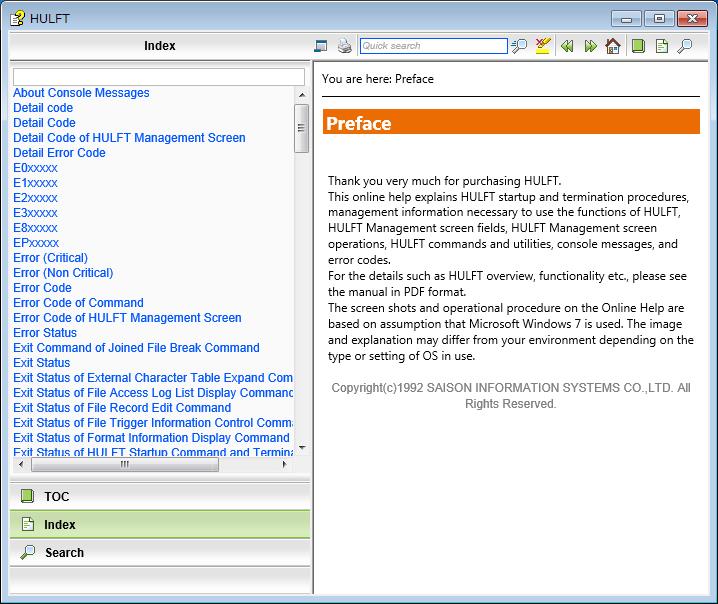
Example: Node.js Debugging with VS Code
Modern IDEs provide seamless integration with debuggers. For Node.js development, you can debug directly from an editor like VS Code.
1. Launch Configuration: Create a `launch.json` file in your project’s `.vscode` directory. This tells the VS Code debugger how to start your application.
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Launch Program",
"skipFiles": [
"<node_internals>/**"
],
"program": "${workspaceFolder}/src/index.js"
}
]
}2. Set a Breakpoint: Click in the gutter to the left of a line number in your `index.js` file to set a breakpoint.
3. Start Debugging: Go to the “Run and Debug” panel and press the green play button. The application will start and pause execution when it hits your breakpoint. You can then inspect variables, view the call stack, and step through the code line by line.
This same principle applies to TypeScript debugging and framework-specific scenarios like Express debugging.

Example: Python Debugging with PDB
For Python development, the built-in Python Debugger (`pdb`) is a powerful, if simple, tool. To use it, you can insert a tracepoint directly into your code.
import pdb
def complex_calculation(a, b):
result = a / b
# Something is going wrong here with certain inputs.
# Let's inspect the state right before the return.
pdb.set_trace()
return result
# When you run this script, it will pause at pdb.set_trace()
# and drop you into an interactive debugger in your terminal.
final_value = complex_calculation(10, 0) # This will cause a ZeroDivisionError
When the script hits `pdb.set_trace()`, it will pause and you’ll get a `(Pdb)` prompt in your terminal. You can type variable names to inspect them (`p a`, `p b`), execute code, or use commands like `n` (next line), `c` (continue), and `q` (quit). This is fundamental for Python debugging and is invaluable for frameworks like Django debugging or Flask debugging.
Weather Prediction: Proactive Debugging and System Resilience
The best way to handle a hurricane is to see it coming and prepare. In software, this means building resilience and observability into your system from the start. This involves a combination of automated testing, static analysis, and designing for failure.
Testing and Debugging: A Symbiotic Relationship
A robust test suite is your first line of defense. Testing and debugging are two sides of the same coin.
- Unit Test Debugging: When a unit test fails, it provides a highly controlled environment to debug a specific piece of logic. You can run the failing test in debug mode and step through the function to quickly find the flaw.
- Integration Debugging: Integration tests reveal issues at the boundaries between components or services. A failing integration test often points to mismatched expectations, incorrect API contracts, or environmental configuration issues.
- CI/CD Debugging: When tests fail in your Continuous Integration pipeline, it can be tricky to debug. Tools that allow you to SSH into the CI runner or run the build in a local Docker container that mimics the CI environment are essential for diagnosing these problems.
Static and Dynamic Code Analysis
Code analysis tools can catch entire classes of bugs before the code is ever run.
- Static Analysis: Linters (like ESLint for JavaScript or Flake8 for Python) and static type checkers (like TypeScript or Mypy) analyze your source code without executing it. They can find potential null pointer errors, unused variables, and logical inconsistencies, acting as an early warning system.
- Dynamic Analysis: Profiling tools and memory leak detectors run alongside your application, monitoring its behavior. They are critical for memory debugging and performance analysis, helping you spot issues like excessive memory consumption or slow database queries that could bring down your system under load.
Debugging in Modern Environments
The rise of containers and orchestration has introduced new layers of complexity.
- Docker Debugging: Debugging an application inside a container can be challenging. Techniques include attaching a debugger to a running process inside the container, using Docker’s logging drivers to aggregate logs, or building debug-enabled images that include necessary tools.
- Kubernetes Debugging: In a Kubernetes environment, problems can occur at the pod, node, or cluster level. Kubernetes debugging involves using `kubectl logs` to view container logs, `kubectl exec` to get a shell inside a running pod, and tools like Istio or Linkerd for observing inter-service communication.
Conclusion: Becoming a Storm Chaser
Viewing a massive, system-destabilizing bug as a “Hurricane Cat 5 From Space” reframes the challenge from a simple coding error to a complex system failure. Taming it requires a methodical, layered approach. You must start from the “space” view with comprehensive logging and debugging and robust error monitoring to understand the storm’s scope and trajectory. From there, you zoom in, using powerful interactive debug tools like breakpoints and profilers to enter the eye of the storm and analyze the core mechanics of the failure.
Ultimately, the most effective strategy is proactive. By embedding resilience into your development lifecycle through rigorous testing and debugging, leveraging static analysis, and designing for observability, you can build systems that are not only less prone to catastrophic failure but are also far easier to diagnose when issues inevitably arise. By mastering these debugging techniques, you transform from someone caught in the storm to a skilled storm chaser, capable of navigating, understanding, and ultimately dissipating the most complex bugs your software can produce.




Molestias neque repudiandae aperiam blanditiis sed non sint ut. Debitis voluptas illum provident id quas.
Iste facere et impedit aut et. Et voluptatum reprehenderit eos nesciunt esse vero est. Deleniti sit omnis odit quia facilis nostrum. Adipisci similique qui quo id harum.
Mauris quis elit malesuada, imperdiet mauris vel, elementum lectus. Integer feugiat imperdiet suscipit. Suspendisse at maximus quam, nec accumsan lectus. Curabitur dapibus imperdiet enim mollis malesuada.