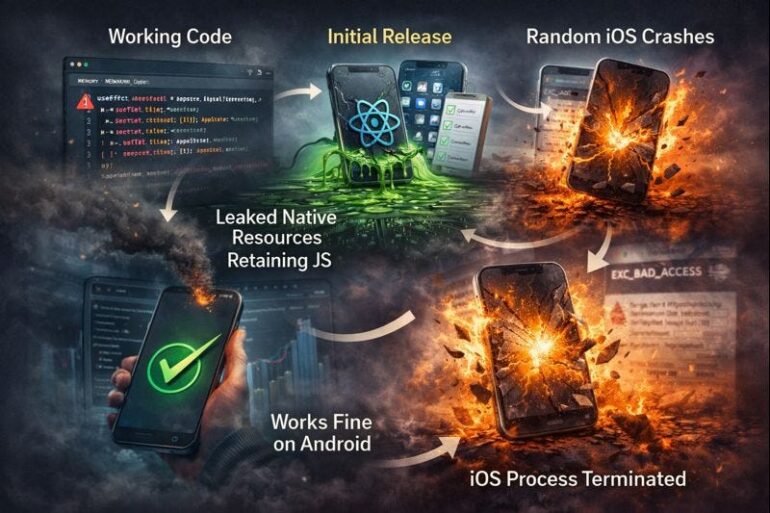
Actually, I should clarify — I’ve spent the last six months trying to get a swarm of autonomous agents to actually do what they’re told without crashing my API budget or getting stuck in infinite loops. It’s been… educational. But I’ve wanted to throw my M3 MacBook out the window at least three times a week.
Here’s the problem: we’re still writing AI agents like they’re simple scripts. You know the drill—instantiate a client, send a prompt, parse the JSON, maybe call a tool, repeat. It works for a demo. But it falls apart the second you try to run three of them in parallel or handle an interrupt signal.
And we don’t need more “frameworks” that just wrap API calls in syntactic sugar. What we need is an OS. Or at least, a runtime kernel that treats agents like processes and context like RAM.
The “Context is RAM” Mental Model
Think about it. An LLM’s context window is finite resource, just like physical memory. If you let an agent run wild, it’s going to segfault—or rather, ContextWindowExceededError—pretty fast. Probably in 2026, we shouldn’t be manually truncating strings.
I started building a lightweight kernel in Python to manage this. The idea is to use asyncio to handle scheduling, but wrap the LLM interactions in a “syscall” interface. This lets us pause agents, swap their memory (context) to disk (vector DB), and prioritize tasks.
import asyncio
import uuid
from dataclasses import dataclass, field
from typing import Callable, Coroutine, Dict, Any
@dataclass
class AgentProcess:
pid: str
name: str
memory_usage: int = 0 # Token count
status: str = "idle"
class AgentKernel:
def __init__(self):
self.processes: Dict[str, AgentProcess] = {}
self.message_bus: asyncio.Queue = asyncio.Queue()
async def spawn(self, name: str, agent_coro: Callable[[str], Coroutine]):
pid = str(uuid.uuid4())[:8]
process = AgentProcess(pid=pid, name=name)
self.processes[pid] = process
print(f"[*] Spawning PID {pid}: {name}")
# We wrap the coroutine to track its state
try:
process.status = "running"
await agent_coro(pid)
except Exception as e:
print(f"[!] PID {pid} crashed: {e}")
process.status = "crashed"
finally:
if process.status != "crashed":
process.status = "terminated"
async def syscall_llm(self, pid: str, prompt: str) -> str:
"""
The 'System Call' for LLM access.
This is where we enforce rate limits and context quotas.
"""
process = self.processes.get(pid)
if not process:
raise RuntimeError("Segfault: Process not found")
# Simulate Context Management (paging)
token_cost = len(prompt.split()) * 1.3
if process.memory_usage + token_cost > 8000: # Hard limit
print(f"[!] PID {pid} OOM Kill: Context exceeded")
raise MemoryError("Context Window Exceeded")
process.memory_usage += int(token_cost)
# Simulate network latency to LLM provider
await asyncio.sleep(0.1)
return f"LLM Response to '{prompt}'"
# Usage Example
async def worker_agent(pid: str):
kernel = get_active_kernel() # Singleton access pattern
print(f"[{pid}] Requesting resources...")
response = await kernel.syscall_llm(pid, "Analyze this data")
print(f"[{pid}] Got: {response}")
async def main():
kernel = AgentKernel()
global get_active_kernel
get_active_kernel = lambda: kernel
async with asyncio.TaskGroup() as tg:
tg.create_task(kernel.spawn("DataMiner", worker_agent))
tg.create_task(kernel.spawn("Summarizer", worker_agent))
if __name__ == "__main__":
asyncio.run(main())Why This Beats the “Chain” Approach
I used to chain functions together using standard libraries. And it works for linear workflows. But last Tuesday, I had a situation where the “DataMiner” agent (from the example above) hallucinated a URL that hung the connection for 60 seconds. Because I was running it sequentially, the entire system locked up.
With the kernel approach, the scheduler just context-switches to the “Summarizer” agent while the miner waits on I/O. It’s basic OS theory applied to LLMs, but nobody seems to be doing it. Everyone is just stacking await calls and praying.
The FIFO Queue Bottleneck
One major gotcha I ran into: standard Python asyncio.Queue is FIFO (First-In-First-Out). And in an autonomous system, this is actually terrible.
If you have a high-priority “Stop” signal or a “User Interrupt,” it gets stuck behind fifty low-priority “log this debug message” tasks. I had to rip out the standard queue and implement a Priority Queue for the message bus.
import heapq
from dataclasses import dataclass, field
@dataclass(order=True)
class PrioritizedItem:
priority: int
data: Any = field(compare=False)
class SignalBus:
def __init__(self):
self._queue = []
self._event = asyncio.Event()
self._lock = asyncio.Lock()
async def push(self, data: Any, priority: int = 10):
# Lower number = Higher priority
async with self._lock:
heapq.heappush(self._queue, PrioritizedItem(priority, data))
self._event.set()
async def pop(self):
while True:
async with self._lock:
if self._queue:
return heapq.heappop(self._queue).data
await self._event.wait()
self._event.clear()
# Usage
# await bus.push("Normal log", priority=10)
# await bus.push("HALT EVERYTHING", priority=0)Benchmarking the Overhead
Yes, but not where it matters. I benchmarked a raw API call script against this kernel architecture. For a single request, the raw script is obviously faster—about 2ms of local processing time versus 15ms for the kernel overhead.
But that’s the wrong metric. When I scaled to 50 concurrent agents performing a “Research & Report” loop:
- Raw Script: Crashed after 4 minutes due to rate limits (429 errors).
- Kernel Approach: Finished in 2 minutes 15 seconds.
Why? Because the kernel’s syscall_llm method (seen in the first snippet) acts as a centralized traffic controller. It throttles requests locally before they ever hit the API, queuing them up intelligently. The raw script just spammed the endpoint until it got banned.
The “Context Paging” Future
Right now, we are manually managing what goes into the prompt. It feels like managing memory in C back in the 90s. malloc this, free that.
But I suspect by mid-2027, we won’t be writing prompt templates anymore. We’ll just point an agent at a data source, and the runtime will handle paging relevant chunks in and out of the context window automatically based on attention scores.
For now, though, if you’re building autonomous systems in Python, stop writing scripts. Start building a kernel. It’s more work upfront, but debugging a race condition in a 100-agent swarm is a nightmare you want to avoid. As I’ve discussed in Agent Debugging: Building a Logic Stack Trace with SQLite, properly managing agent state and context is crucial for effective debugging.