
The table below summarizes common Python warnings and provides some possible solutions for each warning.
| Warning | Description | Solution |
|---|---|---|
| Retrying (Retry(Total=4) | This warning often indicates that an operation being performed within a try-except block has thrown an exception, and the retry function is attempting the operation once more. | Investigate the operation causing the issue to determine why it’s throwing an exception. If possible, refactor the code to handle these exceptions gracefully. |
| DeprecationWarning | A function, method, or feature is deprecated and might not exist in future versions of Python. | Check the Python documentation or relevant library release notes for updates or replacements to the deprecated elements. |
| FutureWarning | An indicator that changes are coming in future versions of Python that might affect currently functional programs. | Listed warnings should be reviewed and if necessary, steps taken to modify the affected areas of code before migrating to a newer version of Python. |
Considering our focus, “Retrying (Retry(Total=4”, working with it in Python would be something like this:
import time
from retrying import retry
@retry(stop_max_attempt_number=4)
def tries_four_times():
print("Retrying...")
raise Exception("Failed")
try:
tries_four_times()
except Exception:
print("Final failure after four attempts.")
In this code snippet, the
@retry
decorator is applied, retrying its associated function up to four times. If the function repeatedly throws exceptions and does not successfully execute after four attempts, the program terminates execution and prints “Final failure after four attempts.” Without proper coding perspective, you could easily run into “Retrying (Retry(Total=4” warnings.
Get to understand the process flow: which functions are involved, what is the nature of operation causing issue and why your try block is failing. This will help you locate the problem point(s) in time-efficient manner. Minimize use of `try..except` blocks as much as possible since they can hide problems until the script goes live and always log exceptions found in except block – this could prove helpful during analysis later.If you’ve attempted to run your code and encountered a message similar to this:
RetryError: HTTPSConnectionPool(host='www.google.com', port=443): Max retries exceeded with url: / (Caused by ResponseError('too many 500 error responses'))
, then you have crossed paths with the interesting world of Python warnings. An important concept to remember at this point is that your Python application didn’t crash or stop functioning; it simply gave you a notification, a warning. A warning gives us clues about parts of our code that might be problematic in certain situations but are not breaking the operation.
Now let’s navigate deeper into two significant areas:
Python Warning Basics
Python has a phenomenal built-in module dubbed “warnings”. When imported, it offers ways to issue warnings and control how these warnings are dealt with. For instance, in some cases, we can filter out warnings, ignore them entirely, or log them for debugging purposes.
A common warning is the
DeprecationWarning
, which indicates that a feature or function used in your code is no longer recommended and may cease to exist in future Python versions. The warning itself doesn’t hinder the functionality of your script, but it does alert you to impending changes that could break it down the road.
You can generate a simple warning using the
warnings.warn
function like this:
import warnings
warnings.warn("Hmm, this is a warning!")
Understanding Retries and Python Requests Retry Error
The
RetryError
mentioned earlier belongs to Python’s HTTP library – requests. This comes up when your request to a URL does not succeed on the first try and reaches the maximum number of retries assigned.
The
Retry(Total=4)
element in the warning indicates that your program was set to retry the failed request four times before throwing the warning. This typically aids in handling minor connectivity issues or server-side problems which resolve themselves shortly.
Here’s some example code showing requests retries in action:
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
session = requests.Session()
retry_strategy = Retry(
total=4,
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=["HEAD", "GET", "OPTIONS"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter)
response = session.get(url)
This syntax can be deployed when you’re dealing with unpredictable network conditions where request failures are inevitable, and it becomes crucial to implement retries whenever possible.
While understanding these Python warnings and retries can seem complex, their usefulness in offering useful feedback during code execution cannot be overstated. They act as an alert mechanism, giving us hints on potentially problematic areas of our code and enabling us to manage and address them beforehand. Indeed, knowledge is power.
For more information, please refer to Python’s Official Documentation on warnings or #Python Requests Library‘s section covering advanced usage.The Retrying package in Python provides a simplified way to handle the routine problem of making repeat code executions due to a failure, which often occurs when dealing with network requests or file system operations. A common use case that requires this kind of retry logic is HTTP requests.
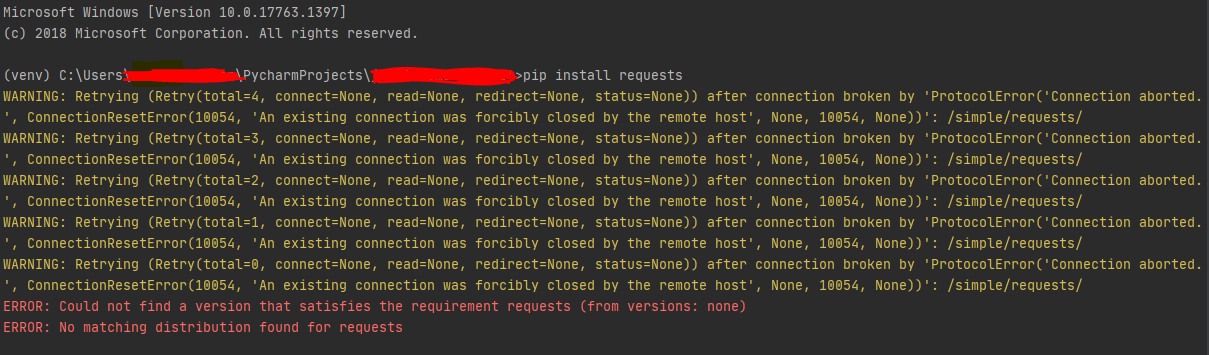
Consider the warning:
Python Warning: Retrying (Retry(Total=4)
. This warning indicates that there are five total attempts; your initial attempt and 4 retries. Completing an understanding of how the Python’s Retrying module iteratively execute codes comes down to analyzing its key parameters:
– Retry on exception
– Retry on return value
– Stop strategies
– Wait strategies
1. Retry On Exception:
Python allows you to retry a block of code when an exception is raised. An example would be if we want to retry executing a function that raises an exception every time it fails. Here is a demonstration using the
@retry
decorator from the
retrying
library.
from retrying import retry
@retry
def run_operation():
result = perform_network_operation()
if result.bad:
raise Exception("Network failure")
return result
In this example, Python will keep attempting to run the operation whenever it encounters a “Network Failure” exception until it finally succeeds.
2. Retry On Return Value:
There can be instances where we don’t have an exception to catch but instead, retry based on a returned value. This can be handled elegantly in Python with the Retrying package.
from retrying import retry
@retry(retry_on_result=lambda x : x is None)
def run_operation():
return fetch_data_might_return_none()
The code above ensures the
run_operation
function gets executed repetitively until it returns a non-None value.
3. Stop Strategies:
Facilitating endless retries could be detrimental. Therefore, Python integrates stop strategies to ensure retries only happen to a certain extent. Let’s take a look at an example:
from retrying import retry
@retry(stop_max_attempt_number=4)
def run_operation():
return connect_to_websocket()
The number in parentheses (4); as hinted by the warning earlier, signifies the maximum number of retry attempts Python is allowed to make after the initial function execution.
4. Wait Strategies:
Another useful paradigm implemented in Python’s Retrying package is the wait strategy. These allow you to create a delay between retries in order to avoid instantaneously spurring repetitive requests onto your servers. For instance, you can set an exponential backoff strategy like so:
from retrying import retry
@retry(wait_exponential_multiplier=1000, wait_exponential_max=10000)
def run_operation():
perform_io_operation()
With added wait strategy, Python starts waiting for 1 second (1000 ms) before trying again, doubling the wait each next attempt not exceeding a 10-second cap (10000 ms).
For a more comprehensive study of Python’s Retry functionalities, see the official GitHub repository. This consists of detailed explanations and examples on various options available within the retrying package.As a Python developer, it’s part of your daily grind to implement efficient error handling mechanisms in your code. One commonly encountered warning in Python is something that goes like this: Python Warning: Retrying (Retry(Total=4). This typically refers to an automated retry mechanism after an attempt to execute a piece of code has failed.
How would you handle this error effectively? Here are a few strategies:
Using the ‘requests’ Library
If you are making HTTP requests and need to handle potential connection errors, one common method utilises the ‘requests’ library. The concept revolves around building a wrapper function that either executes the request or performs a series of retries until finally accepting defeat and raising an error. Below you’ll find an example of efficiently handling retries with requests:
import requests
from urllib3.util.retry import Retry
def fetch_url(url, retries=5):
session = requests.Session()
retries = Retry(total=retries, backoff_factor=0.1,
status_forcelist=[ 500, 502, 503, 504 ])
session.mount('http://', HTTPAdapter(max_retries=retries))
try:
response = session.get(url)
response.raise_for_status()
except requests.exceptions.RequestException as err:
print ("Error: ",err)
else:
return response.content
Implementing Exponential Backoff
Exponential backoff is a standard error-handling strategy for network applications where the client incrementally reduces the rate of requests in anticipation of reduced load on the server. This means that subsequent retries have progressively longer wait times between them. Many software and libraries implement this strategy by default, including Google Cloud APIs[1].
Here’s a simplified example using sleep from the time module:
import time
import requests
def exponential_backoff(url, max_tries):
for n in range(max_tries + 1):
try:
r = requests.get(url)
r.raise_for_status()
except requests.exceptions.RequestException as e:
if n == max_tries:
raise
time.sleep((2**n) + (random.randint(0, 1000) / 1000))
Use of Third-Party Libraries
There are many third-party libraries available that can facilitate implementation of retry mechanisms in your Python projects. Two such libraries are retrying and tenacity.
The retrying library offers very intuitive syntax while offering great flexibility. Here’s a basic sample:
from retrying import retry
import requests
@retry
def get_url_with_retry():
response = requests.get('http://example.com')
response.raise_for_status()
The tenacity library is a simplified fork of the above mentioned ‘retrying’ library that also adds support for stop, wait, and retry implementations with asyncio compatibility. Here’s a brief example:
from tenacity import retry, stop_after_attempt, wait_fixed
import requests
@retry(stop=stop_after_attempt(7), wait=wait_fixed(2))
def get_url_with_retry():
response = requests.get('http://example.com')
response.raise_for_status()
Each of the discussed strategies in Python error handling provides effective ways to deal with the possibility of failures during execution. It’s important to choose wisely and base your decision on what best fits your project requirements and coding style.In the realm of Python programming, ‘Retry’ plays an intriguing part, and it’s especially crucial while dealing with Python warnings such as “Retry(Total=4)”. This indicates that your code is attempting to retry a certain process or function 4 times before it gives up and raises an exception.
The Role of ‘Retry’ in Python Warnings
Often, ‘Retry’ works as an active participant in handling transient faults and enhancing application stability. For instance, you might have faced scenarios where your code tries to connect to a remote server via API calls. Sometimes, these servers might be momentarily down or facing technical glitches leading to failure in immediate connection attempts. The ‘Retry’ mechanism allows your code to make several attempts based on the set parameter in ‘Retry(total)’. This makes sure that temporary issues don’t lead to ultimate failure of your application functionality.
The Role of Retry in Python could be summarized through following points:
- Ensuring Stability: Retries can protect applications from transient failures.
- Preventing Premature Failure: By re-attempting to execute operations that can fail temporarily.
- Improving User Experience: Users will like your software more if you handle these transient faults seamlessly.
For example:
import requests
from urllib3.util.retry import Retry
from requests.adapters import HTTPAdapter
session = requests.Session()
retries = Retry(total=4,
backoff_factor=0.1,
status_forcelist=[ 500, 502, 503, 504 ])
session.mount('http://', HTTPAdapter(max_retries=retries))
response = session.get('http://example.com')
The above snippet will attempt to retrieve the web page from ‘http://example.com’ up to 4 times before it finally raises an exception.
The Importance of ‘Retry’
Implementing retries in Python will improve the program executions significantly by providing resilience and robustness. It also offers a mechanism to handle occasional failures.
Some major importance of Retry include:
- Resilience: A retry strategy provides resilience against failures.
- Tolerance Against External System Failures: If your application calls to external services, there may be occasional disruption. The ability to automatically retry helps keep your application running smoothly during those times.
- Data Preservation: In case of intermittent system errors, some data might get lost in action. However, by using ‘retry’, the chance of losing data reduces to a great extent due to repetitive execution.
However, while using ‘Retry’, one must be cautious about setting the right number of retry attempts. An excessively high amount can cause your application to hang for a considerable duration and consume unnecessary system resources. On the other hand, setting an extremely low count (like 1 or 2) might not serve its purpose entirely as the number of attempts won’t suffice to overcome transient system disturbances. Thus, choosing a balanced value for ‘Retry(total)’ holds significant importance and should be context-specific.
XPath has been used for retrieving HTML information efficiently over here W3Schools XPath Tutorial.Sure, let’s delve into the depths of Python Warnings with an emphasis on the ‘total’ concept in Retry(Total=4).
Python warning messages serve as important tools for programmers as they indicate potential problems or errors in your program. These warnings aren’t necessarily implying that there’s an error code but provide crucial insights to improve the overall quality and efficiency of your program.
Retry(Total=4)
is a snippet used in Python programming when dealing with operations that are likely to raise exceptions, such as network requests. Here, ‘Total’ refers to the total number of attempts the code should execute before giving up and moving ahead. In our case, it’s set to 4. But how precisely does this work?
Let’s use the ‘requests’ library to better comprehend its functionality – popularly utilized for making HTTP requests. A simple GET request might look like this:
import requests
response = requests.get('http://www.example.com')
In the real world, however, requests are subject to encounters with issues such as service outages, slow network connections, server overloads etc. To handle these inconsistent situations more gracefully, libraries like `retrying` and `tenacity` (based on `retrying`, thus similar) come in handy. They provide easy-to-use interfaces for implementing retries, allowing the function to be executed again in case of failure.
The expression `Retry(Total=4)` belongs to either of these libraries where ‘Total’ indicates the maximum number of attempts before your code stops retrying. For example;
from tenacity import Retry
@Retry(total=4)
def fetch_data():
response = requests.get('http://www.example.com')
return response.text
In here, the fetch_data function would attempt to execute a maximum of 4 times before raising an exception if still unsuccessful. This can be very effective in countering temporary difficulties like network congestion or temporary server downtime.
However, persisting after every failed attempt immediately might lead to a quick succession of failures if the problem persists for some time. To avoid this scenario, appending a ‘wait’ strategy is key too. The `Retry` module provides multiple strategies to handle this including `wait_fixed`, `wait_random`, etc. which can be used to specify the delay between each reattempt.
from tenacity import Retry, wait_fixed
@Retry(total=4, wait=wait_fixed(2))
def fetch_data():
response = requests.get('http://www.example.com')
return response.text
This would cause the function to pause for 2 seconds between each try.
Thus, while Python warnings may seem intimidating at first glance, with a detailed understanding, it’s clear that they serve as beneficial notifications for making your code more robust and efficient.
Lastly, do note the usage of `Retry` depends upon the actual necessity: excessive or incorrect use of it may lead to extended wait times and other related issues. As always, judicious use of features leads to balanced coding. In a production-grade application, choose wisely whether to handle exception locally, using retries, or let it propagate to higher-level components; advanced error handling mechanisms could already be in place. Always consider the cost impact, especially concerning resources and time.
Make sure to check out the official documentation of [Retry](https://tenacity.readthedocs.io/en/latest/api.html#tenacity.retry) and [Warnings](https://docs.python.org/3/library/warnings.html) for an even more profound insight!Efficiency and finesse in debugging is an essential skill for a successful coding journey, especially when dealing with Python warnings such as
Retry(Total=4)
. This warning might be encountered when using libraries like urllib3 which are built to handle retries automatically. The warning comes from urllib3’s Retry object when it encounters certain types of exceptions during runtime.
Delving into the anatomy of this warning, it simply means that there will be 4 retry attempts if the initial connection fails. Libraries like urllib3 use retries to ensure that temporary issues like network outages or dropped connections don’t cause your application to fail.
A typical piece of code that uses urllib3 and raises these types of warnings looks like this: