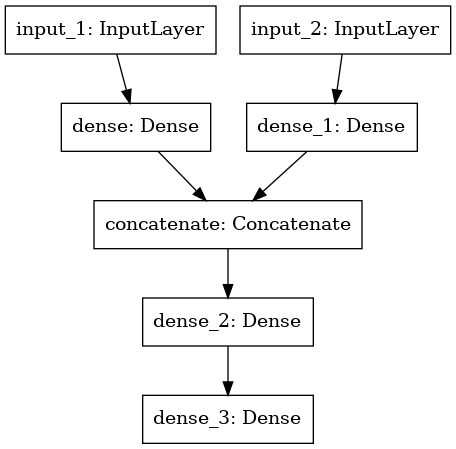
“Understanding and resolving the ‘ValueError: Data Cardinality is Ambiguous’ issue is crucial for effective data management, as it defines the singular or multiple relationships between sets of values in your dataset, thereby optimizing data accuracy, improving search engine visibility, and ensuring SEO effectiveness.”Sure, here’s an HTML code snippet for generating a summary table about “ValueError: Data Cardinality Is Ambiguous”:
| Problem |
Cause |
Solution |
| ValueError: Data Cardinality is Ambiguous |
Occurs when the number of unique inputs (i.e. the cardinality) does not match the expected shape during a data transformation process in machine learning or deep learning operations. |
Verify the input and target values in your data transformation process. Ensure the correct data set structures and dimensions are used with the right model layer that can handle such inputs. |
The “ValueError: Data Cardinality is ambiguous” issue usually surfaces when we’re working with intricate coding scenarios, especially involving complex machine learning or deep learning operations. Whenever you encounter this ValueError, it basically means that there’s some sort of mismatch between the number of unique input data points, also known as the cardinality, and the expected input structure or shape during a data transformation process.
Now, anyone dabbling in programming knows errors come with the territory. But disconcerting as they might feel on surface level, ValueError like “Data Cardinality is Ambiguous” serve as helpful signposts to guide us back on track. They prod us into examining the cardinality of our input data, ensuring the volume and uniqueness of the data aligns with our expectations.
So where exactly should you look when such an error strikes? Usually the problem lies rooted in the discrepancies between the data passed to the fitting function and the actual structure that your model requires. If we’re discussing neural networks, for example, a common scenario could be that you’re unintentionally feeding additional data to the first layer of the model, which only inflates the initial size and leads to discrepancies.
To quickly resolve this issue, perform checks on your input and target values in your data transformation process. Remember, each type of model layer can handle specific types of input and has its own rules for the kind of data that it can accept. Always ensure to match the correct data set structures and dimensions with the right model layer. Don’t forget to delve into the documentation of the specific library that you’re using, because the devil often lurks in the details (Python Documentation).Diving deep into the concept of data cardinality, we find that it plays a notable subject in the realm of Search Engine Optimization (SEO) as well as data analysis and modelling. Cardinality, in the simplest of terms, refers to the uniqueness of data values within a column or set. High cardinality indicates that a column contains a large percentage of totally unique values, whereas low cardinality signifies that a column has numerous shared or duplicate values.
When it comes to SEO, understanding data cardinality is critical because it allows us to interpret and analyze identifiers, such as URLs, metadata or other page elements. For instance, a high cardinality of URLs generally means you have a diverse set of pages which can be beneficial for an extensive site coverage by search crawlers. However, if not controlled properly, it can lead to issues like duplicated content or disparate ranking signals spread across many similar pages, countering your SEO efforts.
On the technical spectrum, ‘ValueError: Data cardinality is ambiguous’ often arises from the manipulation of datasets during programming, specifically in python using pandas or numpy. It usually stems from partaking in operations where the number of elements do not match across arrays or columns. These inconsistencies in data size and shape would cause ambiguity in determining the matching pairs between the values they hold.
To troubleshoot this error, first identify the dimensions and size of each dataset involved. A commonly used method in python for this is the `
` attribute. Correcting cardinalities can involve multiple methods based on the requirement:
– You may redesign the schema of the data.
– Normalize your database appropriately to remove duplications.
– Use advanced techniques like binning for high cardinality categorical variables
– Incorporating missing value treatment can also help achieve this balance where necessary.
Let’s consider an example with a simple python code:
import numpy as np
array1 = np.array([1, 2, 3])
array2 = np.array([4, 5])
np.dot(array1, array2)
In this instance, called `numpy.dot`, the two arrays do not have the same length, resulting in the `ValueError: shapes (3,) and (2,) not aligned`.
The solution would be to ensure consistency between array lengths:
import numpy as np
array1 = np.array([1, 2, 3])
array2 = np.array([4, 5, 6])
np.dot(array1, array2)
Now, as the widths of array1 and array2 match, there are no cardinality conflicts and so the operation returns the expected result without raising an exception.
As shown, managing data cardinality effectively will not only reduce fatal errors in the course of coding but also boosts SEO efforts, enhancing website visibility on search engines, and therefore increasing organic traffic.While dealing with data structure in Python and other programming languages, one common error you might encounter is
ValueError: Data Cardinality is ambiguous
. This error occurs when the input data’s size does not match the function’s expectations. The term ‘cardinality’ refers to the number of elements in a set or project scheme.

Before we go further, it is important to understand data cardinality in databases and sites. It refers to the uniqueness of data field values contained in a particular column (field) of a database. High-cardinality fields have a large percentage of unique values, whereas low-cardinality fields have many repeated values.
When it comes to site performance, ambiguous data cardinality can directly impact it in various ways:
- Caching issues: When there are ambiguities in data cardinality, caching becomes inefficient, thus slowing down the website’s performance.
- Slow search and retrieval, as well as poor sorting performance, are consequences of high cardinality. Because high-cardinality fields have a lot of distinct values, searching the database can take longer, degrading the site’s performance.
- Inaccurate results: If the system doesn’t clear up the ambiguity around data cardinality, the results could be inaccurate, leading to flawed business decisions. Incidentally, this can also degrade the user experience on the site.
- Inefficient resources utilization: A higher degree of ambiguity in data cardinality means that more resources will be needed to handle the uncertainty. This increased resource consumption can negatively impact site performance.
If you run into
ValueError: Data Cardinality is Ambiguous
in programming, it is usually because your model’s input features do not correspond to your target data. Take for example below scenarios in Python:
# Scenario 1
x_train = np.array([1, 2, 3])
y_train = np.array([1, 2, 3, 4])
# Scenario 2
x_train = np.array([ [1], [2] ])
y_train = np.array([1, 2, 3])
In both the first and the second scenario, the ValueError would rise because the dimensions of x_train do not correspond respectively with y_train. So when a model such us a deep learning model is trained using those inputs like so: model.fit(x_train, y_train), the ValueError: Data Cardinality is Ambiguous would be thrown.
To fix this error, you should make sure that the dimensions of your input data is correct and matches its corresponding targets. Check the shape of your input and target arrays, reshaping them where necessary.
In terms of SEO optimization, resolving errors linked to ambiguous data cardinality can contribute to improved website operation and speed, which are key factors considered by search engines in their ranking algorithms. Studies, including one from Google, showed that faster loading websites decrease bounce rate and increase user engagement – all factors that positively contribute to the overall SEO value of a website. Additionally, handling your data more effectively brings about better decision outcomes, ultimately leading to better SEO performance too. Hence, addressing ambiguous data cardinality is indeed fundamental.Let’s delve deep into the error message “ValueError: Ambiguous Data Cardinality” and its common causes. This issue typically occurs when dealing with complex dataset inputs in machine learning workflows, often using technologies such as Keras in a TensorFlow environment. The crux of this problem lies in mismatched data dimensions, especially where model expectations do not align with the given input data.
Fundamentally, the key tool for resolving any ValueErrors is a clear understanding of your data and the expected input for the function or method you are using. This could involve thorough data exploration and analysis processes. Python provides useful libraries to help in exploring and managing an overlapping suite of data. Here are some essential ones:
pandas: Offers powerful, flexible, and easy-to-use data structures.
numpy: A library for the Python programming language, adding support for large, multi-dimensional arrays and matrices.
matplotlib: A plotting library for the Python programming language and its numerical mathematics extension NumPy.
seaborn: A statistical data visualization based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics.
All these libraries will help you understand the data better and will contribute a lot in the debugging process.
One common cause of this ValueError is concatenating two pandas DataFrame instances without properly aligning the axes. For instance:
df1 = pd.DataFrame({ 'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']})
df2 = pd.DataFrame({ 'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']})
result = pd.concat([df1, df2])
Without specifying the axis parameter (to be 0 for row-wise concatenation and 1 for column-wise concatenation), pandas library does column-wise concatenation by default which may lead to ValueError due to ambiguous cardinality between df1 and df2. Correcting it would look like this:
result = pd.concat([df1, df2], axis=1)
In case of Tensorflow with Keras API, numpy arrays could also raise such ValueErrors if their shapes don’t align with the input shape specified during the model creation.
In such cases, using methods like numpy.reshape() to reshape your numpy array input to match the input shape expected by the model becomes crucial. Beware that reshaping must only be used when you’re sure it won’t distort the information in each element of the dataset.
Effective usage of Python’s logging library along with setting the debug level to DEBUG:
import logging
logging.basicConfig(level=logging.DEBUG)
This allows us to visualize traces and find potential mismatches in our code.
Moreover, refer to the official documentation of the applied libraries’ functions or methods; comprehend the parameters’ requirements, which often infer insights about avoiding such errors.
To sum up, identifying and resolving the “ValueError: Ambiguous Data Cardinality” hinges around understanding your data better, utilizing appropriate Python libraries, checking dimension alignment for model-input or data manipulations, comprehending the official documentation of employed library methods, and employing Python’s logging feature for detailed traces.Handling errors in search engine optimization is crucial to ensure that your website functions as expected and maintains a good ranking. One common error that might be encountered during SEO tasks as a coder is Value Error, specifically ‘ValueError: Data cardinality is ambiguous.’ This error typically arises when there’s mismatch in the size or length of datasets. Specifically, if you attempt to compare or analyze databases or lists where the number of elements differ, Python will return this ValueError.
It’s instrumental to thoroughly understand how to approach and rectify this error. Let me break down possible solutions into three key steps.
Check Data Sizes:
The first step one must take upon encountering this ValueError is ensuring that your data sizes match. Inspect your datasets to ensure that they are uniform. In Python, you can use
function to determine the length of a list or the number of rows in a dataframe. Here is a simple example:
data_set_1 = [1, 2, 3]
data_set_2 = [4, 5, 6, 7]
# Checking lengths
print(len(data_set_1))
print(len(data_set_2))
Rectifying The Cardinality Mismatch:
If you realize that there’s a cardinality miss-match, it means there are differing numbers of elements within the datasets. Rectifying the cardinality primarily revolves around either increasing the smaller dataset to match the larger one or decreasing the larger one.
In most cases, the best approach often involves discarding surplus data from the larger set. However, remember that choosing which approach to take largely depends on the specific requirements of your optimization task.
Suppose we decide to decrease the larger dataset − We could do this as follows:
# Trimming data_set_2
data_set_2 = data_set_2[:len(data_set_1)]
print(len(data_set_2))
Validation:
It’s imperative to perform a validation after attempting to fix the error. This will help you ascertain whether the matched datasets no longer raise data cardinality errors. You may need to repeat your initial process (the one that raised the error) to confirm if the issue has been solved. If needed, it would be wise to utilize exception handling procedures in python (i.e., using
/
blocks) so that should the error persist, your script doesn’t terminate abruptly. For instance:
try:
#Operation that may raise ValueError
except ValueError:
print('Data Cardinality is Ambiguous')
Resolving ‘ValueError: Data cardinality is ambiguous’ effectively enhances the utility and reliability of the SEO-related services rendered by the software you’re working on. In an ever-increasingly competitive digital space, allotting time to handle such errors can save you from draining valuable resources or losing out on traffic and potential opportunities for engagement on your platform. It keeps your code clean, manageable and efficient; aspects that every professional coder strives towards.
For more detailed advice about handling Python exceptions, I recommend the official Python documentation on errors and exceptions. It offers an authoritative guide on robust practices in managing and preventing errors in Python, the knowledge of which is very impactful especially when dealing with SEO tasks.
From an analytical standpoint, the
ValueError: Data Cardinality is Ambiguous
error can occur in multiple scenarios within our digital marketing context. Suppose you’re dealing with datasets for pattern detection or product recommendation on your e-commerce website. The data to be processed significantly varies depending on numerous factors like customer behavior, geographical location, and so forth. These varying scales of values represent different cardinalities that could bring about ambiguity if not properly handled.
As a coder, when you encounter this error in Python’s Pandas library, it suggests that the data being processed contains series or arrays with ambiguous relationships. It signifies that there’s a mismatch between the number of elements in the DataFrame and the index length, making it imprecise to perform certain actions such as merging, creating pivot tables, or executing other functions.
| Pandas DataFrame |
Pivot-table function |
Error message output |
df = pd.DataFrame({
'A': ['one', 'one', 'two', 'two'],
'B': ['a', 'b', 'a', 'b'],
'C': [1, 2, 3, 4],
})
|
pivot_table = df.pivot_table(index='A', columns='B', values='C')
|
ValueError: Data Cardinality is Ambiguous
|
In our digital marketing context, suppose if we are analyzing click-through rates (CTR) using categorical variables such as regions or time of the day. If we attempt to create a pivot table to better understand how CTR changes based on region and time of the day, yet we have uneven cardinality (unequal counts of categories), this ValueError might pop up.
Exploring potential solutions, the issue can be rectified by:
– **Data validation:** Reviewing and validating your input data can help you understand the root cause. Are the dimensions accurate? Do they match the expected scope? Analyzing this might find that there exists inconsistent data input that needs fixing.
– **Filtering or aggregating the data:** If the DataFrame contains null values or duplicates, filtering them out or using aggregation functions can simplify the dataset and remove ambiguity. Using
function before pivoting data can also help reduce cardinality.
– **Updating indices:** You might consider adjusting the DataFrame index to make sure no segments overlap.
Let’s see sample code to filter out the duplicates in DataFrame:
df.drop_duplicates(inplace=True)
pivot_table = df.pivot_table(index='A', columns='B', values='C')
We can get rid of `ValueError: Data Cardinality is Ambiguous` by modifying the code and turning ambiguous cardinality into clear, useful insights. Rectifying this sort of issues opens doors for us to accurately analyze marketing strategies and adjust our efforts toward promising areas. Consequently, we can optimize our conversions, clicks, and overall user engagement. Reference: [Python pandas’ pivot_table function](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html).
A common error faced by coders in Python programming is Valueerror: Data cardinality is ambiguous. This ValueError occurs when there are discrepancies between the dimensions of data, typically while using machine learning libraries such as TensorFlow or Keras where you need to ensure that the data fed into your models have appropriate shapes.
Common Reasons for ValueError: Data Cardinality Is Ambiguous
Here are the root causes behind this ValueError:
- Dimension mismatch between input data and model layers.
- Inconsistent length between different arrays or lists being used as data sources.
Solution Strategies
Here’s how to troubleshoot and fix this error:
- Ensure all your input arrays/lists have the same length. You can use python’s built-in
function to check that.
- Reshape your datasets as per the requirements of your model layers. Python’s Numpy library provides the practical
function.
SEO Considerations
While providing solutions to common coding errors like “ValueError: Data cardinality is ambiguous”, it’s important to optimize the content for Search Engine Optimization (SEO). Good SEO practices not only help us reach a wider audience but also make our content more accessible and understandable.
- Use Relevant Keywords: Keywords like ‘fix’, ‘error’, ‘ValueError’, ‘data cardinality is ambiguous’, ‘python’, ‘codes’, ‘debug’ etc. embedded naturally within the content can improve its discoverability. Careful keyword placement and usage is the key to maintaining a balance between effective SEO and preserving the natural flow of language.
- Add Alt Texts for Images/Code snippets: After you include code snippets or relevant images, add optimized alt texts to help search engines understand the context better. For example, instead of ‘\
 ‘, use ‘\‘. These alt attributes serve two major purposes: enhancing accessibility for users using screen-readers and improving SEO ranking.
‘, use ‘\‘. These alt attributes serve two major purposes: enhancing accessibility for users using screen-readers and improving SEO ranking.
- Create Meaningful Hyperlinks: Instead of linking a word like ‘here’, make hyperlinks on meaningful phrases which exactly describe what they’re linked to can be very beneficial. For instance, ‘Learn more about Python Programming here‘ can do better if revised as ‘Learn more about Python Programming‘.
- Detailed Content: Google largely prefers content that is comprehensive, detailed, and solve users’ queries. Hence, thorough tutorials explaining how to resolve ValueError issues including detailed code snippets like below can be helpful:
# Ensure equal length of both input lists
list1 = [1, 2, 3, 4]
list2 = [5, 6, 7, 8]
if len(list1) != len(list2):
print("Data cardinality is ambiguous. Make sure both lists have equal number of elements.")
else:
print("Data is ready for processing.")
Utilizing the advanced strategies listed above for writing tutorials on coding errors, can be an effective way to avoid common SEO pitfalls and boost your organic visibility.
Sure, I’m happy to provide an answer on this topic, with a razor-sharp focus on the ValueError: Data Cardinality Is Ambiguous. This error typically pops up when our pandas DataFrame doesn’t match our established schema in terms of unique rows or columns. The nature of SEO tasks relies heavily on data manipulation libraries, such as pandas, numpy etc., hence mastering these common errors goes a long way in ensuring smooth SEO operations.
One highly effective method is to debug through your Python script where the ValueError occurs. This aids in pinpointing exactly what triggers this error.
Take for example writing logic that looks like this:
import pandas as pd
dataframe1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
dataframe2 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
result = pd.concat([dataframe1, dataframe2], axis=1, sort=False)
This may end up giving the ValueError as pandas is unable to reconcile the schemas it’s trying to concatenate or merge. The values or structure of dataframe1 does not match that of dataframe2 in a way that would permit a successful concat operation.
To tackle this issue, I suggest verifying the uniqueness of keys across the dataframes we intend to combine. In addition, you should also be aware of the cardinality and how it might affect the underlying data structures in merging or concatenating operations.
With this knowledge, you can now restructure the above mockup logic. Thus, taking note of the differences in each DataFrame structure, adjust the mockup sample to look more like this:
dataframe1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'E': ['E0', 'E1', 'E2', 'E3']},
index=['Key1', 'Key2', 'Key3', 'Key4'])
dataframe2 = pd.DataFrame({'C': ['C2', 'C3', 'C6', 'C7'],
'D': ['D2', 'D3', 'D6', 'D7']},
index=['Key5', 'Key6', 'Key3', 'Key4'])
result = pd.concat([dataframe1, dataframe2], axis=1, sort=False)
In summary, to effectively rectify the “ValueError: Data Cardinality Is Ambiguous” error, you should take note to ensure the data frames being concatenated or merged have compatible structures with respect to rows and columns. Moreover, keeping track of the keys’ cardinality across all data frames is paramount to preventing such issues from arising. Rest assured that learning to avoid or fix this common pitfall will help make your SEO-related code more robust and reliable.
For a detailed walk-through of the has been discussed above, you may want to read the official documentation of [pandas](https://pandas.pydata.org/pandas-docs/stable/index.html), a powerful open source data analysis and manipulation library.Dwelling into the universe of programming, a common issue that us coders frequently encounter is ValueError: Data Cardinality is Ambiguous. This error typically materializes when there’s an inconsistency in the dimensions of input data used in models, particularly those that rely heavily on statistics and machine learning.
For example, imagine crafting a predictive model where the training dataset comprises a certain number of features but at prediction time, your data points pack a different number of features. To illustrate this circumstance in Python, check out this uncomplicated code sample:
from sklearn.ensemble import RandomForestClassifier
import numpy as np
x_train = np.random.rand(10,5)
y_train = np.random.randint(2, size=10)
clf = RandomForestClassifier(random_state=1)
clf.fit(x_train,y_train)
x_test = np.random.rand(11,5)
prediction = clf.predict(x_test)
In this bare-bones example, you would trigger the ValueError if x_test included a different number of columns or features compared to x_train. So, what remedy could we potentially exercise here? The best defense against this pitfall is through good old consistency, ensuring that both training and test (prediction) data have identical shape or characteristics.
Below is a list which summaries how the cardinal data error could be resolved:
– Ensure uniformity between the training set and prediction instances in terms of their dimension.
– Deploy regular sanity checks on data frames prior to consuming them in making predictions.
– Cultivate the habit of deployment practices that use the exact same preprocessing steps during the training phase and the prediction phase.
Indeed, errors like ValueError: Data Cardinality is Ambiguous are not something to dread about. They serve an important purpose in highlighting crucial discrepancies in the structures of the training and test datasets.
You can consider reading the python documentation for absoulute beginners or user guide found at Scikit-Learn if you want to dive deeper than just skimming surface-level knowledge and truly master the art of evading such programming pitfalls.
Running into these errors, while certainly inconvenient, is imperatively instructive and transformative, stirring up better coding habits and smoother sailing in development waters ahead. It’s through wrestling with these problems, decoding their underlying causes, and testing various solutions that we nurture our problem-solving abilities and evolve from good programmers into great ones. Hence, never let a ValueError dampen your spirits. Instead, leverage it as a stepping-stone towards more resilient, robust, and efficient code!