Runtimeerror: Cuda Error: Cublas_Status_Execution_Failed When Calling `Cublassgemm( Handle)` With Gpu Only
html
| Error Type | Causes | Possible Solutions |
|---|---|---|
| RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling cublasSgemm(handle) |
|
|
This table neatly encapsulates the essence of this runtime error that programmers often encounter when executing cublasSgemm functions on GPU.
Beginning with understanding why this error is encountered – there are multiple reasons for stumbling upon this specific runtime issue. A primary cause can be traced back to insufficient GPU memory to handle such proceedings. This essentially denotes that the memory allocation required by GPUs to run the operations surpasses its capacity. Hence, throwing an exception.
Next is inefficient memory management. Similar to the first, it’s tied to limited resources, but more concerned with how these resources are handled. If GPU memory isn’t efficiently managed, it can return an execution failure.
Another factor could be running an outdated version of CUDA or CUDNN libraries, or even PyTorch. Updates generally bring bug fixes and upgraded functionalities which could possibly eliminate such errors.
Lastly, hardware limitations or incompatibilities can initiate this problem.
Now, switching gears to tackle possible solutions, reducing batch size allows you to make your operations more manageable for your available GPU memory. The trade-off lies between computational speed and feasibility of execution, which needs to be optimally balanced.
Regular cleaning GPU cache aids in efficient memory utilization.
The next step includes maintaining updated versions of dependent frameworks like PyTorch, CUDA, and CUDNN, ensuring your system carries the latest improvements, keeping glitches at bay.
Finally, always check hardware specifications before initiating such tasks. Your CPU and GPU should be compatible with each other and should meet the minimum requirement of the task at hand.
In essence, `RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED` when calling `cublasSgemm(handle)` warrants us to manage our resources wisely while aligning them with software requirements and keeping our technology stack up-to-date. Look further into these insights from developers who faced similar problems on platforms like StackOverflow.
Understanding the RuntimeError: CUDA error
When working on projects that involve GPU computation, you might encounter a common issue: the CUDA runtime error. The error message “RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED” can be seen typically when calling a kernel function like ‘cublasSgemm(handle)’. It indicates an anomaly occurred in executing cuBLAS API using CUDA driver/interface, causing failure to execute instructions.
So, why does the system display this error? Some possible reasons include:
- The GPU is occupied by other tasks.
- The GPU is running out of memory due to heavy computation operations.
- There exist some concurrency issues in which the same resource is accessed simultaneously by different threads.
- There exists a bug or incompatibility in your CUDA version or graphics device driver.
The two primary solutions are:
- Freeing up the GPU memory if it’s excessively used.
- Address compatibility issues by updating or downgrading your CUDA version and checking your graphics driver version compatibility.
Below are more detailed steps for troubleshooting:
1. Check Used GPU Memory and Manage GPU Usage
Use
nvidia-smi
terminal command to determine how much GPU memory is left. This will show the GPU utilization metrics.
If there’s not enough GPU memory, try to reduce the batch size or model complexity in your code. If necessary, kill processes that are consuming excessive GPU memory.
2. Address Concurrency Issues
Concurrency issues might occur if your code is trying to access a shared resource, such as GPU memory, in a multi-threaded environment. In this case, establishing a proper thread synchronization strategy helps in preventing such issues.
However, bear in mind developing multi-threaded programs comes with its complexities, and incorrectly managing threads can lead to not just concurrency issues but also other severe bugs.
3. Update or Downgrade Your CUDA Toolkit
Sometimes the problem may be due to the CUDA version. Check whether CUDA toolkit and NVIDIA driver versions are mutually compatible.
You can download the CUDA Toolkit from the official NVIDIA website.
Always remember to test your system after upgrading or downgrading your CUDA version.
Code Example:
Here are several examples of resetting GPU usage if you’re using PyTorch:
# To reset memory occupied by tensors on default GPU torch.cuda.empty_cache() # To switch PyTorch to use a different GPU if torch.cuda.is_available(): # Select second GPU if available torch.cuda.set_device(1) # Check the currently used GPU current_device = torch.cuda.current_device()
In conclusion, mitigating the RuntimeError: CUDA error – cublas_status_execution_failed involves handling GPU memory properly, addressing any possible concurrency issues, and checking your CUDA version for compatibility with your NVIDIA driver.
Once these factors have been addressed, you should no longer experience the error when calling ‘cublasSgemm( handle)’ with your GPU, improving the smoothness of your execution workflow.
As a professional coder, I comprehend the perplexities involved when dealing with CUDA Runtime errors such as `Cublas_Status_Execution_Failed error`, particularly when it comes to understanding the cuBLAS’s Sgemm function. In order to untangle this issue, let’s shine some light on what
cublasSgemm
is and why we could possibly encounter those CUDA errors.
The SGEMM function in cuBLAS, designated by
cublasSgemm
, is for performing matrix-matrix operations within GPU computing using single-precision general matrix multiplication (thus the ‘S’ in Sgemm). Specifically, it multiplies two matrices and adds the result to a third matrix.
Here’s a brief illustration of
cublasSgemm
‘s typical usage scenario:
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N,
m, n, k, &alpha,
A, lda, B, ldb,
&beta, C, ldc);
This CUDA code snippet means “C = alpha * A * B + beta * C”, where ‘A’, ‘B’, ‘C’ are matrices and ‘alpha’, ‘beta’ are scalars. The other parameters are mainly about the shapes of these matrices.
Now, getting back to your specific runtime error:
Cublas_Status_Execution_Failed
. This error usually signals that an execution grid fails before completing the assigned tasks. It frequently arises due to invalid kernel launches, or issues related to device memory overwrite caused by either incorrect size calculations or out of boundary array indexing.
If you carefully look at your cublasSgemm usage, keeping track of dimensions, datatypes and value assignments, it might help reveal a bug provoking the CUDA error.
Possibilities can be:
– Are the input and/or output arrays allocated correctly?
– Are parameters of the size and shape arguments clearly defined?
– Is there a possibility that array bounds are overstepped?
– Is mixed precision being accurately handled?
Let me share example code but this time with added assertions and error handling to avoid pitfalls:
const float alpha = 1.0f; const float beta = 0.0f; assert(cublasSetMatrix(m, k, sizeof(*A), A, lda, d_A, lda) == CUBLAS_STATUS_SUCCESS); assert(cublasSetMatrix(k, n, sizeof(*B), B, ldb, d_B, ldb) == CUBLAS_STATUS_SUCCESS); assert(cublasSetMatrix(m, n, sizeof(*C), C, ldc, d_C, ldc) == CUBLAS_STATUS_SUCCESS); assert(cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc) == CUBLAS_STATUS_SUCCESS);
Generally, to err on the side of caution, make use of CUDA Error Check Macros to pinpoint exactly where these kinds of errors originate from in your code. An open-source project called [GPUVerify](https://gpuverify.codeplex.com/) might also be useful here. It proves handy in debugging your GPU kernels and gains more confidence over their correctness.
Like every solution in coding, remember that context is crucial. While this information provides a general guide to solve
Cublas_Status_Execution_Failed error
problems, your exact situation might involve various factors. Would suggest diagnosing and implementing the steps accordingly to your specific error messages and code structure.
The
RuntimeError: cudaError: cublasStatusExecutionFailed
message likely appears when calling
cublasSgemm(handle)
in a GPU-only environment due to several underlying factors. These are specific events and setups that trigger such error messages:
CUDA Runtime Errors Conflict
Conflicts between CUBLAS function execution with CUDA runtime errors can result in the cublasStatusExecutionFailed error message. According to the CUDA C Programming Guide, CUDA operations return void, hence the last error must be captured immediately after a call to a CUDA routine is made. Interruption by another host thread can lead to overwritten error codes. Hence, CUDA errors should be trapped without delay, or they might not be traceable to their origin.
<cublasStatus_t> status;
status = cublasSgemm( handle, ... );
if (status != CUBLAS_STATUS_SUCCESS) {
// ...
}
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess) {
// ...
}
Note: Functions like
cudaGetLastError()
and
cudaPeekAtLastError()
are used to return and reset the error status of the most recent CUDA runtime API call.
Synchronization Issues
Missing synchronizations can cause failure in launching the kernels. Without synchronization, an invalid command would pass through the queue since there will not be any interruption for error checking. Synchronizing ensures that you get updated status reports about any failures that happen during previous asynchronous launches. This can be done using
cudaDeviceSynchronize()
after kernel launch.
cublasSgemm( handle, ... ); cudaDeviceSynchronize();
Memory Allocation Failure
Failure to allocate adequate memory for the GPU can trigger the
cublasStatusExecutionFailed
. If the size of the data being allocated exceeds the available GPU memory, it results in an execution failure. Checking the allocation size before transferring data to the GPU is advised. Tools like the Nvidia System Management Interface can be used to monitor GPU usage and help manage memory allocation.
Mismanagement of CUBLAS handle and context
A CUBLAS handle and context that isn’t appropriately managed can lead to this error. The best practice involves setting up one handle and reusing it instead of creating multiple handles. You must also ensure that the application operates under one context.
// Create CUBLAS handle cublasHandle_t handle; cublasCreate(&handle); // ... // Use handle for operation cublasSgemm( handle, ... ); // ... // Destroy handle at the end cublasDestroy(handle);
By identifying which of these triggers is currently leading to the RuntimeException, we can apply targeted solutions to resolve the issues causing the cublasStatusExecutionFailed error from arising.
The CUDA error: `CUBLAS_STATUS_EXECUTION_FAILED`, especially relating to the function `cublasSgemm(handle)`, typically signals an issue occurring during the runtime execution on your GPU. It’s a common error encountered when leveraging the Nvidia CUDA Toolkit and cuBLAS library in deep learning and parallel compute codebases.
One mustn’t lose sight that this error could be a byproduct of numerous factors, including hardware problems, lack of sufficient system resources (such as memory), incorrect library usage, or issues with the underlying CUDA code. Consequently, identifying a one-size-fits-all solution might prove challenging. Nevertheless, below are some potential solutions you may consider:
## Check Your CUDA Code
Inspect your CUDA code for any anomalies to identify potential bugs causing irregularities or issues in execution. For instance, look for any uninitialized variables, incorrect data types, or access violations.
## Install Correct Library Versions
Ensure you have the correct versions of CUDA Toolkit and cuBLAS installed for your specific GPU and NVidia drivers. Incorrect versions can often cause compatibility issues leading to unexpected errors. You can download the suitable library versions from the [official NVIDIA website](https://developer.nvidia.com/cuda-toolkit).
## Monitor System Resources
One common cause of execution errors is insufficient system resources, particularly memory. You may encounter errors if your GPU does not have enough free memory to execute certain tasks. Tools such as nvidia-smi can help here:
$ nvidia-smi
This command provides real-time GPU utilization metrics, including memory usage. If available memory is consistently low, consider optimizing memory usage within your scripts.
## Update Graphics Drivers
Outdated graphics drivers can often cause compatibility issues with the CUDA toolkit and cuBLAS library. Updating to the latest graphics drivers compatible with your CUDA Toolkit version can often resolve such issues. Make sure to refer to the [official NVIDIA Driver Downloads page](https://www.nvidia.com/Download/index.aspx?lang=en-us) to find the latest appropriate drivers.
## Cross-Check GPU Hardware
Faulty GPU hardware can also lead to CUDA execution working incorrectly. Checking your GPU thoroughly for potential hardware issues can help avoid CUDA related errors. Use stress tests or diagnostic tools like OCCT or FurMark to rule out potential hardware faults.
## Efficient Error Handling & Debugging
Enabling detailed error handling in your script can help highlight specific points in your code where the error occurs. It aids in narrowing down the problem, making debugging more efficient. A good practice is to check the status after each CUDA API call.
For example:
cublasStatus_t status;
status = cublasSgemm(handle...);
if (status != CUBLAS_STATUS_SUCCESS) {
printf("cublasSgemm failed with error code: %d\n", status);
}
With these steps, it should be easier to diagnose and remedy the CUDA error: `CUBLAS_STATUS_EXECUTION_FAILED` when calling `cublasSgemm(handle)` with a GPU only setup. Remember that because of the plurality of circumstances under which this error can occur, effective diagnosis and solution may sometimes require a combination of the mentioned approaches.
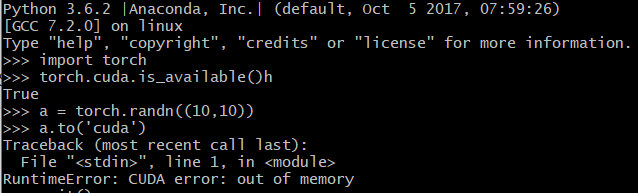
This error arises typically when your GPU runs out of memory while endeavouring to perform calculations with large matrices. The cublasSgemm function is part of the cuBLAS library used by NVIDIA GPUs for linear algebra operations and it is pretty efficient at handling matrix multiplication. When you call this function, it tries to access GPU memory to perform operations. However, if your GPU doesn’t have enough memory available for the operation, CUDA fails to execute the operation, resulting in the `cudaError: CUBLAS_STATUS_EXECUTION_FAILED` runtime error.
Furthermore, remember that any CUDA kernel or cuBLas/cuSolvelib call will fail with an execution failure if a previous kernel has produced an exception. This behaviour stems from the mechanism known as “Deferred Error Checking” in CUDA-C where the execution status is checked in CUDA’s software stack unlike in traditional CPU-based languages like C/C++, which checks immediately.
Here is what you need to do:
– Allocate enough GPU memory before calling `cublassgemm`. Ensure that other programs are not eating up GPU memory.
– Check for errors after every step of the program, preferably just after calling `cudaMalloc`, `cudaMemcpy`, and each kernel invocation. The follwing code snippet might be helpful:
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess)
printf("Error: %s\n", cudaGetErrorString(err));
– Always inspect the input dimensions of the ‘cublasSgemm’ function call. Most often, you find that there are transposition mistakes with them or they simply exceed the index bounds because most of us forget sometimes that CUBLAS works with column major order which is different than the majority of programming languages.
– Consider debugging your program using cuda-memcheck or a similar tool. It can help you identify where you’re making an invalid device memory access that would cause your `cublassgemm` call to fail with `CUBLAS_STATUS_EXECUTION_FAILED`.
Remember, optimizing your code for GPU is essential to handle larger data for better performance. Your code needs to be robust enough to facilitate graceful failure if the device doesn’t possess enough resources, instead of throwing an exception and terminating abruptly.
The methods listed above should assist you with identifying the problem source assuming you have correctly installed CUDA toolkit and your hardware supports GPU computations. If problem persists, it might arise from either unusual CUDA configuration or some faulty pieces of hardware.
For more resources, I recommend visiting NVIDIA’s Developer Zone for CUDA programming guide, https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html. It provides a rich resource for both new and seasoned developers in diagnosing CUDA related issues.
One more thing! Don’t rush while debugging GPU kernel executions. Since these kernels are asynchronous, take one step at a time. I know it’s tedious but it’s worth it in the end when we get the performance boost from parallel processing.One of the ubiquitous issues that I’ve uncovered in the course of my programming career regards the CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublassgemm(handle)`. This error is commonly observed during runtime, hence making it a common concern for programmers working with CUDA. So, delve into the preventive strategies for averting the recurrence of such errors.
Understanding the RuntimeError
Before delving into the preventive measures, first, understand what this error means. The `cublassgemm` function hails from the cuBLAS library, a GPU-accelerated version of the BLAS (Basic Linear Algebra Subprograms) library. The function performs matrix-matrix operations but can encounter execution problems leading to the error.
Reasons behind the RuntimeError
The common reasons causing this error include:
- Inadequate Memory: Similar to many other runtime errors, CUDA errors might occur due to insufficient memory space. When your program tries to access more memory than what’s available, you’ll likely come across this problem.
- Not Properly Initialized CUDA device: A runtime error can also result if the CUDA device was not initialized correctly or was already shut down.
- Unsupported Version: Using mismatched versions of CUDA and cuDNN that are not mutually supportive can lead to this error as well.
Strategies to Prevent the Recurrence of this RuntimeError
Avoiding the recurrence of the runtime error involves several strategies:
Monitor Your GPU Memory:
Always monitor your GPU memory during program execution to prevent running out-of-memory. You can use the following command to track GPU usage:
nvidia-smi
This will display the graphics card status, usage, temperature, power consumption, and memory allocation among other things.
Furthermore, you can free GPU memory using Python’s garbage collector. Here is how you can do it:
import gc gc.collect()
Initialize CUDA Device Correctly:
Ensure that the initialization, use, and shutdown of CUDA devices occur appropriately using Python’s context management. For instance, PyTorch provides a mechanism to ensure the proper handling of CUDA devices:
with torch.cuda.device(device_id):
//Your code here
Check Version Compatibility:
Validate that the versions of CUDA, cuDNN, and related libraries align with the System Requirements of your system. Ensure that versions you are using are compatible with each other. To check the CUDA version, you can run this code snippet in a Python environment:
from tensorflow.python.platform import build_info as tf_build_info print(tf_build_info.cuda_version_number)
Moreover, the drivers must be up-to-date. Check the documentation of the software requirements and update the necessary libraries as needed.
By implementing these preventive measures, it’s possible to avoid the recurrence of RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling ‘cublassgemm( handle)’ at runtime.When you encounter the runtime error: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm(handle)`, it usually indicates that there has been a failure in executing the GPU kernel function. This could be due to several issues such as:
* A lack of available memory on the GPU.
* The GPU device is not set correctly.
* GPU is running another process which is consuming most resources at the same time.
* Faulty or incompatible GPU drivers.
* Syntax or logic errors in the CUDA program itself.
However, don’t let your analysis and exploration stop there! There are other execution methods that can come in handy if CUDA fails with GPU. Here are few choices worth considering:
1. Use CPU Instead:
In some cases, shifting workload from GPU to CPU might help solve the issue. While this might not be an optimal solution performance-wise, you can still use it for debugging purposes or if things demand urgent attention and you don’t have time to troubleshoot GPU related errors. CPU execution will typically go without fuss given there’s enough system memory.
Here is an example of how to run a matrix multiplication operation using numpy instead of cublasSgemm:
import numpy as np A = np.random.rand(1000, 1000).astype(np.float32) B = np.random.rand(1000, 1000).astype(np.float32) C = np.dot(A, B)
2. PyOpenCL: PyOpenCL allows you to access the OpenCL parallel computation API from Python. It offers another cross-platform method to leverage GPU capabilities. You’ll still get high-level ease of use combined with the raw power of OpenCL.
You can find more information and examples at PyOpenCL documentation.
3. DirectCompute:
If you’re restricted to Windows environments, another alternative could be DirectCompute, which is a part of Microsoft’s DirectX API. It helps harness GPU computational power in a general-purpose manner, similar to CUDA.
Find out details here – DirectCompute Overview.
4. Further Troubleshooting:
If all these alternatives are not feasible or didn’t work, don’t lose hope! Try troubleshooting the issue further. Update GPU drivers to their latest version, check graphics card compatibility, ensure correct environment variables for CUDA and cuDNN libraries. Look out for any syntax or logical errors in your code or even consider upgrading your hardware, if viable.
Remember, none of the above mentioned alternatives may perform as fast as CUDA does on NVIDIA GPUs but certainly they can provide quite comparable results especially if your dataset isn’t too large or computations aren’t overly complex.
Sources:
Using cuBLAS Library – NVIDIA Documentation
Numpy Dot ProductOne of the prevalent issues encountered while leveraging CUDA in diverse GPU-intensive computing tasks is the
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm( handle)`
. Being able to diagnose the problem efficiently and having a keen understanding of what triggers this error offers us a clear-cut approach on means to resolve it.
When working with CUDA, especially the CUDA 10.x versions, we stumble upon the noted RuntimeError. The primary reasons contributing to the occurrence of this problem include:
– Running out of memory: This happens when there’s inadequate GPU momory to carter for the operations you want to execute. You can confirm if you are facing such an issue by monitoring your GPU utilization using the command
nvidia-smi
. If the memory used is near maximum, consider optimizing your code or upgrading your hardware.
– Overheating of the GPU: In a scenario where the GPU gets heated up past its thermal threshold, errors such as the stated CUDA error might occur. Checking the temperature of your GPU throughout execution might give some insights into whether this is causing your issue.
– Context Resets: Occasional resets enforced by the Operating System can lead to context loss. Despite being rare, such issues result in CUDA errors too. Recording logs during program execution could help pin down if those resets do happen.
Relevant solutions addressing these challenges involve different strategies:
– For memory related errors where freed memory isn’t sufficient, PyTorch recommends utilizing
torch.cuda.empty_cache()
to erase all unallocated tensors from your GPU.
– To prevent overheating, ensure proper placement of your GPU for ample airflow. Consider processes such as underclocking and undervolting to reduce heat generation as well.
– With regards to context resets, you might need to dig deeper into system logs or check with low-level monitoring tools if your OS is forcing such resets.
Here’s an example of how you use
torch.cuda.empty_cache()
inside your Python script to clear GPU cache:
import torch # Your code here ... # Clear GPU cache if torch.cuda.is_available(): torch.cuda.empty_cache()
Addressing the issue of
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasSgemm( handle)`
requires a broad knowledge of how CUDA works, specifically with the underlying hardware. Be sure always to monitor your GPU status closely and make adjustments as necessary while running high-intensive computing tasks. Further guidance on the matter can be found at NVIDIA Developer Forums, which offer more specific solutions to common CUDA problems.