



It’s a common scenario where you have a generous amount of free memory, but your PyTorch application throws a RuntimeError signifying “CUDA Out Of Memory”. This happens due to the separation of CPU and GPU memory – when PyTorch requests memory from CUDA for a given task or calculation, CUDA will try to allocate it from its own memory pool. If there isn’t enough available memory within this specific pool, it’ll throw the said error even though your machine shows a significant amount of free memory overall.
The possible reasons could include:
* Large-sized batches in deep learning models that exceed CUDA’s memory.
* PyTorch’s dynamic computation graph needs space for both tensors and their gradient equivalents, which doubles their size in memory.
* Resolving this involves optimizing your code by using smaller batch sizes, employing lightweight model architectures, etc.
Now, let us construct an HTML summary table encapsulating the above information. Entries would reflect ‘Issues’, ‘Cause’, and ‘Resolution’.
| Issues | Cause | Resolution |
|---|---|---|
| PyTorch RuntimeError: CUDA Out Of Memory with much free memory available | Large batch sizes exceed CUDA's memory pool/PyTorch's resources also accommodate gradient equivalents, doubling memory consumption. | Optimize code, adopt smaller batch sizes, use lightweight model architectures, etc. |
It’s important to note that while mitigating the RuntimeError: CUDA Out Of Memory, striking a balance between the model complexity, batch size, and memory optimization techniques, is paramount for resolving such issues efficiently and effectively.The “CUDA out of memory” error in Pytorch can be quite a challenge to resolve, particularly, when you seem to have a large amount of free memory. But fear not, let’s delve into the depth of this problem and find methods to resolve it.
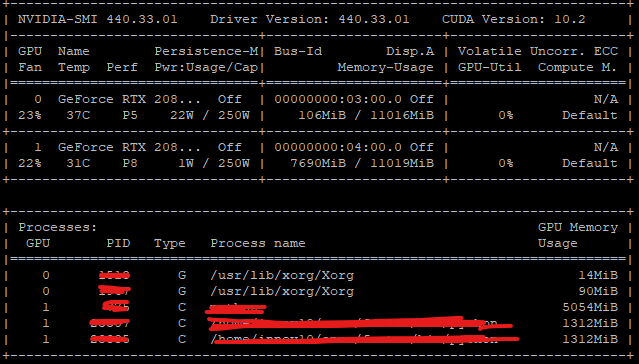
First, we need to understand what is causing this issue. At its basic level, the memory used by PyTorch includes PyTorch tensors and CUDA-related variables that consume GPU resources. This memory allocation takes place because PyTorch leverages the power of your GPU (Graphics Processing Unit) for computation, and a key factor here is the GPU memory usage.
If we dive deep into one typical scenario, the error “RuntimeError: CUDA out of memory” is mainly caused by:
– Constantly adding to GPU memory usage without releasing unused memory.
– Trying to allocate more memory than the available GPU memory.
It’s essential to note here that even if your computer seems to have a significant amount of free GPU memory, there could still be instances where Pytorch may display the “CUDA Out of Memory” error!
Now let’s consider solutions to handle this “CUDA Out of Memory error”:
– Manage CUDA Cache: It might be beneficial to manage your CUDA cache regularly using
torch.cuda.empty_cache()
, which will help release any unused memory on your GPU.
– Reduce Batch Size: Another approach to resolving this would be to work with a smaller batch size. You may need to experiment with your batch size to determine the optimal quantity which neither compromises training performance nor exceeds memory usage.
– Avoiding the Unnecessary use of .to(device): Refrain from unnecessarily converting data or model parameters to GPU using
.to(device)
as it leads to increased memory usage.
– Gradient Accumulation: In some cases, Gradient Accumulation can be used where you want larger batch sizes but are limited by GPU memory. By accumulating gradients over multiple smaller batch iterations and updating our model after several steps rather than at each step, we reduce the memory consumption
Consider the following code snippet illustrating gradient accumulation:
loss = model(input)
loss = loss / accumulation_steps # normalization
loss.backward() # backpropagation
if (step + 1) % accumulation_steps == 0:
optimizer.step() # update after multiple steps
optimizer.zero_grad() # reset gradients
– Use Gradient Checkpointing: Gradient checkpointing is another trick often applied to train very deep networks that don’t fit into GPU memory with standard backpropagation. The trade-off here is a significantly reduced memory requirement, at the expense of slightly increased computation time.
Remember that these techniques aim to optimize efficiency by managing GPU memory usage. These will require consistent trial-and-error due to the variability of models and data sizes you may encounter.
For further reading and understanding, documentation provided by Pytorch could prove to be a highly relevant resource.
Running a deep learning model using PyTorch can sometimes lead to a
RuntimeError: CUDA out of memory
, even if there seems to be enough free GPU memory. This is often due to how efficiently the GPUs are utilized. It might not necessarily mean you’re completely out of memory, rather it could be that large chunks of consecutive memory aren’t available.
Here are some techniques to debug and potentially resolve CUDA memory errors:
- Clearing GPU cache: The Pytorch framework has a garbage collector that releases unreferenced memory but the engineer needs to manually direct the GPU to delete unused tensors.
import torch torch.cuda.empty_cache()
Executing this code will clear the GPU cache and may resolve the CUDA out of memory error.
- Reducing batch size: Decreasing the data input batch size may reduce memory usage significantly. Large batches need more memory compared to small ones. You can try reducing it until your program can execute without memory errors.NVIDIA’s Optimization Guidelines recommends this strategy.
- Setting up Tensor Cores: For Volta, Turing, and newer GPUs, Tensor Cores can provide significant training speedup by performing mixed-precision computing. PyTorch supports native automatic mixed precision training which helps maximize throughput and efficiency on such hardware by automatically converting certain ops to run in FP16 instead of FP32, thereby reducing the memory footprint. Example:
model = ... optimizer = torch.optim.SGD(model.pt.parameters(), ...) model, optimizer = amp.initialize(model, optimizer, opt_level='O1') # for dealing with autocasting and gradient scaling together
- Inspect allocated tensors: Keeping track of tensor allocation and deallocation manually can help identify potential memory leaks or points of inefficient memory use. Tools like Pytorch’s Memory profiler can provide detailed breakdowns of where your model is consuming memory.
- Gradient Checkpointing: Gradient checkpointing is a technique to reduce GPU memory usage during model training. It trades off compute for memory. Rather than storing all intermediate activations of the entire computation graph for backpropagation, checkpointed nodes store only a subset of the activations and recompute the others during the backward pass. PyTorch provides utility functions to apply this technique. However, care must be taken to ensure proper handling of networks with multiple inputs or outputs.Grad Checkpointing.
These techniques will help manage GPU memory more effectively when using PyTorch. Though an outright solution might not be present for each case, the mentioned debugging steps have proven quite essential given different scenarios related to CUDA memory errors.
If you’re using PyTorch, one of its powerful features is its dynamic computational graph mechanism. It facilitates creating and manipulating complex neural network architectures by instantiating and changing computation graphs on-the-fly in a flexible yet efficient manner.
However, that dynamism can sometimes cause some unexpected behaviours, particularly around memory usage. Sounds like you’re experiencing an example of this when trying to execute your Python program, where you’ve come across the runtime error:
RuntimeError: CUDA out of memory
, even though you seem to have plenty of free memory available.
It’s worth mentioning that deep learning frameworks running on GPU (like PyTorch) have a somewhat different concept of memory management than what you might be used to. When these frameworks initiate, they usually attempt to pre-allocate almost all the GPU memory for maximum efficiency – it’s much faster to reuse existing space than to allocate new spaces every time. So, your script may not be literally consuming all that memory, but instead, it could be asking the OS for more memory than initially reserved by PyTorch.
There are a couple ways around this if you’re dealing with larger datasets:
* Use
torch.utils.data.DataLoader
: By splitting your data into mini-batches through DataLoader. Instead of iterating over raw data in your training loop, you can handle them in mini-batches which will benefit in terms of performance, code cleanliness, and memory efficiency.
* Optimize your graph construction: Try tweaking other attributes such as adopting a lower precision (float16) or reducing model complexity.
* Switching off Autograd for inference: While building your computation graph, PyTorch keeps track of all operations for backpropagation. But, during evaluating phase these operations are not needed. Therefore, you can use
torch.no_grad()
to temporarily set all the
requires_grad
flags to false.
* Clear up unused tensors: Use Python’s garbage collector alongside PyTorch’s memory freeing functions like
torch.cuda.empty_cache()
to clear up after variables which are no longer in use.
When working in an environment with many GPUs available, it’s also possible your task may be landing on a GPU that’s already heavily utilized. PyTorch offers mechanisms for controlling which device your tensors are created on, so you can ensure you’re using one with sufficient memory capacity:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
This sets the appropriate device to be your default CUDA device if available, and ensures your model parameters live on that device.
For further details on PyTorch’s dynamic computation graph mechanism and how to deal with CUDA Out of Memory errors specifically, refer to the official PyTorch CUDA notes.Sure! Understanding how GPU memory allocation and management work in PyTorch is key to avoiding errors like
RuntimeError: CUDA out of memory
. The main reason this error may occur when there appears to be available memory is due to PyTorch’s default behaviour of caching GPU memory, which it does for efficiency reasons.
This caching provides speed benefits as CUDA operations can utilize cached memory immediately without the overhead of requesting and allocating memory. While this behaviour is generally beneficial, we need to come up with handling strategies to prevent unwanted situations when there is enough GPU memory but our allocation request isn’t fulfilled due to fragmentation.
Memory Fragmentation
GPU memory fragmentation happens when your GPU memory has enough room overall for an incoming tensor but doesn’t have a continuous memory space equal to or larger than the size of the incoming tensor. Because tensors require contiguous blocks of memory, even though there may be sufficient GPU memory left, you might still get an infamous `CUDA out of memory` error. This scenario can often occur during deep learning tasks due to dynamic computational graph construction.
Memory Management Strategies
There are few strategies that you can opt for efficient management of GPU memory:
• Control Memory Cache: Since PyTorch caches GPU memory for performance optimization, you can manually control this by clearing the cache after certain operations where you suspect large memory tensors are not going to be reused. PyTorch allows developers to free-up unoccupied cached memory through the commands
torch.cuda.empty_cache()
.
• Avoid In-Place Operations: In-place operations might increase fragmentation risk because they take up new memory while keeping the old one until the operation has been fully completed. As a general tip, utilise in-place operations judiciously, as excessive use could result in greater fragmentation and `CUDA out of memory` errors.
• Use Mixed Precision Training: Another technique you can use to reduce GPU memory usage is mixed precision training. It involves using both 16-bit and 32-bit floating-point types in a model during training to make it run faster and use less memory. NVIDIA provides the Apex library that supports automatic mixed precision training. It requires less memory thus making large, memory-hungry models fit on the GPU.
Here’s how you can use `empty_cache()`:
import torch # suppose you've finished a training/evaluation iteration, which possibly involves large tensors # ... finished computation ... # Now you can clear memory cache torch.cuda.empty_cache()
And here’s an example of mixed precision training with Apex:
from apex import amp
# Assume model and optimizer exist
model, optimizer = amp.initialize(model, optimizer, opt_level="O1")
# ...
loss = criterion(output, target)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
optimizer.step()
Remember, efficiently managing GPU memory is not just about avoiding errors, but also ensures maximum utility of available resources, which contributes towards lower training times and better performing models.Great, you are experiencing a CUDA out of memory issue even though there appears to be plenty of CUDA memory available. This can occasionally arise when working with large datasets in PyTorch. However, don’t worry! Below are some effective tips you can apply to prevent this error:
– Reducing Batch Size:
Your first line of action should be to reduce the batch size. This is the most common and effective way to cope with memory-related problems when training deep learning models. However, keep in mind this step might potentially affect your model performance as too small a batch size could cause an unstable training process.
Here’s how you should define a smaller batch size:
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=16, # Reduced from 64
shuffle=True)
– Free GPU Cache After Training:
Sometimes, despite having abundant GPU memory, you might still face the ‘CUDA out of memory’ issue because PyTorch doesn’t automatically clear up the GPU cache after each operation or iteration. This CPU memory leak can be avoided by freeing up the unused cache:
torch.cuda.empty_cache()
Call this function anytime you want to free up some space.
– Gradient Accumulation:
Model training often involves several backward passes which can consume substantial memory. By accumulating gradients, performing backpropagation after several forward passes, you can manage memory usage better without compromising on the batch size. Check out the sample code below:
optimizer.zero_grad() # Reset gradients tensors
for i, (inputs, labels) in enumerate(train_data):
predictions = model(inputs) # Forward pass
loss = criterion(predictions, labels)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optimizer.step() # Now we can do an optimizer step
optimizer.zero_grad()
– Use Gradient Checkpointing:
Gradient checkpointing is another RAM-saving technique that trades compute for memory. Specifically, it discards intermediate activations during the forward pass while saving the computations; these saved computations are then re-computed during the backward pass for gradient computation. As a result, less GPU memory is consumed. PyTorch provides a built-in function,
torch.utils.checkpoint.checkpoint()
, for gradient checkpointing. You can read more about the implementation details on the PyTorch documentation.
– Check for Memory Leaks in Your Code:
It’s also possible that the ‘CUDA out of memory’ error is resulting from a memory leak in your code. A memory leak arises when you’re allocating new tensors at each iteration but not releasing them for garbage collection. Keep an eye out for unnecessary tensor storing such as retaining graph history where it’s not required.
with torch.no_grad():
and
.detach()
help in avoiding such situations.
Remember that the underlying causes of ‘CUDA out of memory’ errors vary depending upon the complexity and specific requirements of individual coding scenarios. These approaches may aid you in proactively mitigating and preventing these issues in many general use-cases.
As Stephen Hawking once said, “Intelligence is the ability to adapt to change.” So don’t hesitate to experiment with these methods and possibly develop your bespoke solutions for handling large datasets without getting into the ‘CUDA out of memory’ trouble.Sure, let’s dig into the mechanism of Pytorch’s garbage collector and understand its impact on GPU memory usage. First and foremost, it should be acknowledged that Pytorch’s garbage collector works quite differently from Python’s own garbage collector. Below are some important observations to mention:
For those not familiar with the terms, Pytorch is a deep learning framework (like TensorFlow), CUDA is a parallel computing platform and application programming interface model created by Nvidia, and `torch.cuda` is a PyTorch module offering various functions and classes for interfacing with your GPU through the CUDA API.
How Does Pytorch Garbage Collector Work?
Unlike typical Python objects where once the reference count hits zero the object gets forgotten instantly, Pytorch uses a caching allocator to manage the GPU memory usage of tensors. This means even when you’ve deleted all references to a tensor, Pytorch still keeps the allocated GPU memory in its cache for future use. It’s completely normal to observe an unchanged GPU memory usage after deleting a tensor.
This strategy minimizes the overhead of allocating and deallocating memory at run-time, which can be significant, and allows computation to proceed with minimum GPU memory usage necessary. The cache consequently does not get cleared until the very end of the program.
As a result, Python’s built-in `gc.collect()` may not be helpful in reducing GPU memory consumption.
Here’s an example showing this behavior: