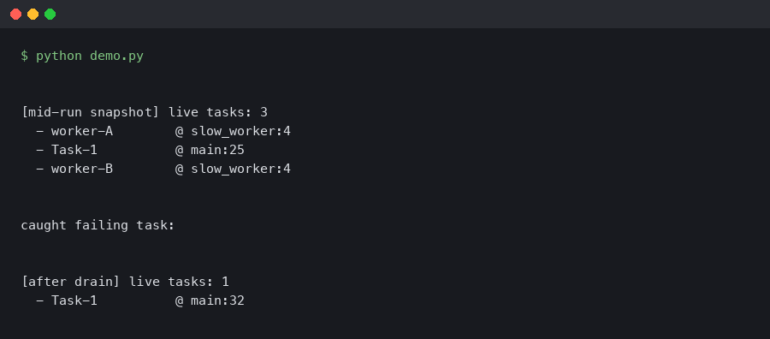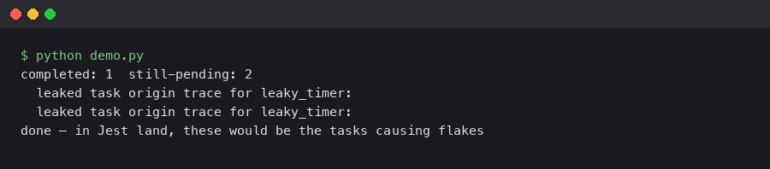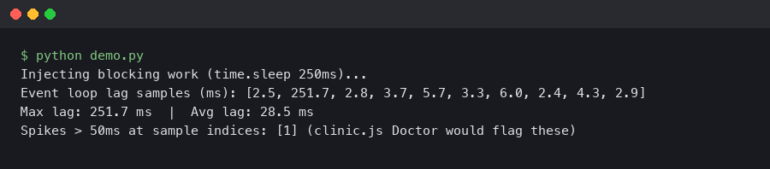

I distinctly remember the moment I stopped trusting my own unit tests. It was 2:00 AM on a Friday, naturally. I was staring at a production log filled with TypeError: Cannot read properties of undefined (reading 'split'). The stack trace pointed directly to a utility function I had written three days earlier. The kicker? That function had 100% code coverage. The build pipeline was green. My local tests passed in milliseconds. According to every metric we track, this code was perfect.
But in the real world, it was crashing the backend pod every time a user pasted a specific weirdly formatted string from an old Excel export. My unit tests checked for strings, nulls, and empty inputs. They didn’t check for a string containing a non-breaking space followed by a control character.
This experience frustrated me to no end. We spend hours writing tests that essentially just confirm what we already know. We test the “happy path” and maybe two or three edge cases we can think of off the top of our heads. It’s confirmation bias encoded in TypeScript. That’s when I realized that standard unit test debugging is often a waste of time because we are debugging scenarios that work, rather than finding the ones that don’t.
The “Happy Path” Trap
The core problem with traditional unit test debugging is that it requires you to predict the failure. You write a test case, it fails, you fix the code, it passes. But what about the failures you can’t predict? In JavaScript Development, specifically with loosely typed data coming from APIs, the permutations of input are infinite.
Here is the function that caused my headache. It looks innocent enough:
function parseUserTag(input) {
if (!input || typeof input !== 'string') return null;
// Logic: extract "tag" from "User: tag"
const parts = input.split(':');
if (parts.length < 2) return null;
return parts[1].trim().toLowerCase();
}And here is the test suite that gave me false confidence:
describe('parseUserTag', () => {
test('extracts tag correctly', () => {
expect(parseUserTag('User: Admin')).toBe('admin');
});
test('handles empty input', () => {
expect(parseUserTag('')).toBe(null);
});
test('handles malformed strings', () => {
expect(parseUserTag('NoSeparator')).toBe(null);
});
});This passes. I get a green checkmark. I push to prod. Then, someone sends a string that technically has a separator but fails on the trim() because of some encoding weirdness I didn’t foresee, or perhaps the split logic behaves differently with surrogate pairs. The point isn’t the specific bug; it’s that I, the human, failed to imagine the input that would break my code.
Injecting Chaos into Jest

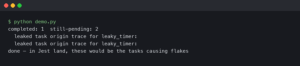
I finally got over this hurdle when I started integrating fuzzing directly into my Jest workflow. Back in early 2025, tooling for this really matured, allowing us to run fuzz tests right alongside standard unit tests without needing a separate, clunky CI pipeline. Tools like Jazzer.js made this accessible, but the concept applies generally: throw garbage at your code until it breaks, then debug the wreckage.
Instead of me guessing what inputs might break parseUserTag, I let the fuzzer generate thousands of inputs per second. It tries empty buffers, massive strings, unicode chaos, and object injections.
Here is how I rewrote the test using a fuzzing approach within Jest:
// parseUserTag.fuzz.js
import { FuzzedDataProvider } from '@jazzer.js/core';
import { parseUserTag } from './utils';
test.fuzz('parseUserTag fuzz test', (data) => {
const input = data.consumeString(100); // Generate random strings up to 100 chars
try {
parseUserTag(input);
} catch (error) {
// If this throws, we found a bug.
// The fuzzer will report the exact input that caused the crash.
fail(Crash detected with input: ${input});
}
});When I run this, I’m not checking for a specific return value (though I could verify properties, like “result should not be null if input starts with ‘User:’”). I am checking for stability. I am debugging for resilience.
Debugging the Crash
This is where the actual Unit Test Debugging gets interesting. When a standard test fails, you usually know why—you changed a variable name or updated logic. When a fuzz test fails, you are often staring at a hex string or a bizarre sequence of characters that makes no sense.
My workflow for debugging these failures has become very specific. The fuzzer usually outputs a “reproduction file” or a seed. This is critical. Without deterministic reproduction, you are just guessing.
I configure my VS Code launch.json to attach directly to the Jest process running the single failing fuzz case. This allows me to use breakpoints inside the library code while the fuzzer replays the exact crash scenario.
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Debug Fuzz Test",
"program": "${workspaceFolder}/node_modules/.bin/jest",
"args": [
"--runInBand",
"${file}"
],
"console": "integratedTerminal",
"internalConsoleOptions": "neverOpen",
"disableOptimisticBPs": true
}
]
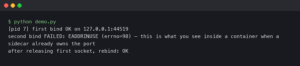
}When I hit the breakpoint, I often find that the input is something like a string containing only a null byte, or a string that triggers a prototype pollution vulnerability I hadn’t considered. The debugger shows me the exact state of the memory when the crash happens.
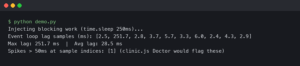
I also rely heavily on coverage reports during this phase. IDEs now support visualizing coverage for fuzz tests. If I see a branch of code that is never hit even after 100,000 fuzzing iterations, I know my fuzzing parameters are too narrow, or that code is dead. Conversely, if the crash happens in a line I thought was unreachable, I’ve just uncovered a serious logic flaw.

Q&A: Why Don’t More People Do This?
I talk to other developers about this workflow, and I usually get the same pushback. It seems like overkill to them. Here are the common objections I hear and my responses.
Q: Isn’t fuzzing just for security researchers?
No. That used to be true, but now it’s just efficient debugging. If you are writing an API that accepts user input, you are doing security work whether you like it or not. I use it to prevent crashes, not just to stop hackers. A crashed server is a bug, regardless of who caused it.
Q: Doesn’t this make the test suite slow?
It can if you run it on every commit. I don’t. I run standard unit tests on every commit (CI/CD Debugging fast path). I run the fuzzing suite nightly or on a separate pipeline. It’s a trade-off. I’d rather burn CPU cycles overnight than burn my weekend fixing a production outage.
Q: I can’t fuzz my entire application.
You shouldn’t. I only fuzz the boundaries—the places where data enters the system. API endpoints, file parsers, and validation logic. Fuzzing a React component’s rendering logic is usually a waste of time. Fuzzing the Redux reducer that handles incoming WebSocket messages is essential.
The Reality of Debugging in 2025

We have access to tools now that make “it works on my machine” an unacceptable excuse. The integration of these tools into standard runners like Jest means we don’t have to learn a new CLI or set up a Docker container just to run a stress test. We can just write test.fuzz and let the computer do the heavy lifting.
I recently used this approach to debug a weird memory leak in a Node.js worker. The standard tests passed fine. The fuzzer, running for 10 minutes, managed to generate a sequence of JSON objects that caused the heap to explode. Debugging that required analyzing the heap snapshot generated at the moment of the crash—something I couldn’t have easily reproduced manually because the sequence required 50 specific steps.
If you are still manually writing every single input case for your unit tests, you are doing the computer’s job. We should be defining the invariants (what must always be true) and letting the machine try to prove us wrong.
A Final Warning
Don’t fall into the trap of thinking this solves everything. Fuzzing is fantastic for finding crashes, uncaught exceptions, and memory issues. It is terrible at finding business logic errors. If your code successfully calculates a tax rate of -50% without crashing, the fuzzer will think everything is fine. You still need traditional unit tests to verify that 2 + 2 equals 4. Use fuzzing to verify that “2 + [Emoji]” doesn’t take down the server.