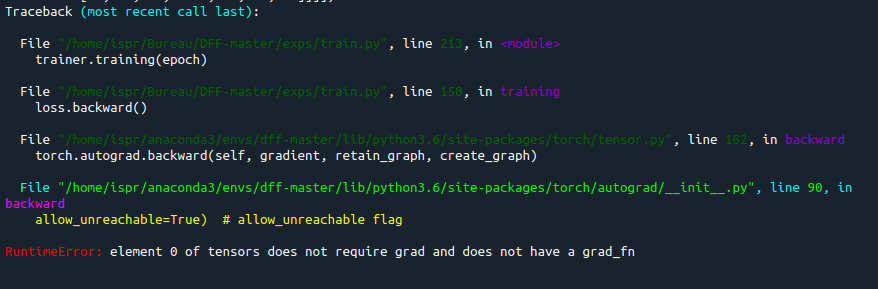

RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn
, which is associated with PyTorch, a popular open-source machine learning framework. Exploring this error requires us to delve into the practicalities of computational graphs and automatic differentiation in deep learning models.
| Error | RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn |
|---|---|
| Description | This error is thrown when you’re attempting to backpropagate through a tensor that has its requires_grad property set to False. |
| Solution | To resolve this error, you should ensure that the tensors being operated upon for gradient computation indeed require gradient calculation. |
To explain further, every tensor in PyTorch has a Boolean property called
requires_grad
. If
requires_grad=True
, it starts to track all operations on it. As soon as you finish your computation, you can call
.backward()
and have all the gradients computed automatically. The gradient for this tensor will be accumulated into the
.grad
attribute.
Now, if there’s one tensor in your neural network that doesn’t expect to have its gradient calculated, then you’re going to encounter the error
RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn
during the backward pass or when calling
.backward()
function. It’s because PyTorch couldn’t find a computational graph node for that tensor.
Consider the following snippet of code:
import torch x = torch.tensor([1.0], requires_grad=False) y = 2*x y.backward()
Executing this will give you the error because we’re trying to compute the gradient for
x
, even though
x.requires_grad=False
.
Fixing the error is simple – just ensure that for the tensor(s) involved in the computation, you’ve set
requires_grad=True
if you intend to compute its (their) gradient(s).
Feel free to dive into the official PyTorch Documentation for a deeper understanding of Autograd: Automatic Differentiation. There, you’ll dive into how PyTorch creates and manipulates computational graphs for gradient computation.In the realm of PyTorch, a popular machine learning library in Python, you may encounter a
RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn
. This issue generally arises when you’re attempting to calculate gradients on variables that aren’t involved in the computational graph for backpropagation or these variables don’t require gradient computation.
Now let’s dive deeper into this error. Each tensor in PyTorch has an attribute called
requires_grad
. If
requires_grad=True
, it begins to track all operations on it. After you finish your computation, you can call
.backward()
and have all the gradients computed automatically. The gradient for this tensor will be accumulated into
.grad
attribute.
Consider the code snippet below:
x = torch.tensor([1., 2., 3.], requires_grad=True) y = torch.tensor([4., 5., 6.]) z = x + y z.backward(torch.ones_like(z))
In this example, we’re computing
z = x + y
where tensor
x
, has
requires_grad=True
but tensor
y
doesn’t. Later on the computation graph, we are calling
.backward()
function on z – which is essentially asking PyTorch to compute the gradient of z w.r.t each tensor in its computational graph that has
requires_grad=True
. But y isn’t part of this graph because it didn’t involve in any operation with
requires_grad=True
.
To tackle the
RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn
ensure you’ve marked all your tensors that need gradients as
requires_grad=True
appropriately in your computational graph. Data you’re feeding into your model that doesn’t require gradients should have
requires_grad=False
. In order to confirm whether a tensor has
requires_grad=True
, you can print the tensor during debugging.
If you want to dig deeper into these concepts visit PyTorch official documentation on [Autograd: Automatic Differentiation]It sounds like you’re dealing with a common error in Pytorch:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
. This typically suggests a disconnect between the computation graph and the tensors you’ve created. Remember, tensors in Pytorch may be either leaf nodes or non-leaf nodes in this graph. Leaf nodes are those that users create, while non-leaf nodes result from operations on these leaf nodes.
The error message is suggesting that the first tensor (element 0) in your list does not have an associated gradient function (
grad_fn
) and doesn’t require a gradient calculation (
requires_grad
is set to False). This situation commonly occurs when attempting to backpropagate through a tensor that doesn’t require gradients.
Piecing this together, your solution needs to address the issue at its root cause: ensuring the correct application of gradient-enabled tensors within your computational graph. Let’s explore some critical steps:
Ensure All Input Tensors ‘Require’ Gradients:
If an input tensor should participate in backward propagation, it needs to have
requires_grad=True
. This flag instructs Pytorch to track all the operations performed on that tensor and compute the gradient value during backward propagation. If you accidentally created tensor without this, you would need to enable it:
input_tensor = torch.tensor(your_data, dtype=torch.float32, requires_grad=True)
Connect Tensors to Computational Graph:
This error could also occur if a tensor originated outside of the computational graph and wasn’t connected properly. Every operation on tensors creates an additional node in the computational graph. Only tensors participating in your model’s calculations should be involved in generating the gradients.
intermediate = input_tensor * 3.0 # Intermediate is now connected to the computational graph. output = model(intermediate)
Avoid In-Place Operations:
Lastly, in-place operations can disorient the tracking of operations by Pytorch, resulting in similar issues. Refraining from using them can prevent potential complications:
Instead of:
tensor += 3.0
You should use:
tensor = tensor + 3.0
This brief analysis covers the probable root causes and corrective actions for the “element 0 of tensors does not require grad and does not have a grad_fn” error. It directs your attention towards the Pytorch tensor properties and illuminates the necessity of proper handling and connection to the computation graph. Applying these insights should help resolve this issue and keep your models training as expected. For more information, consult the official Pytorch Documentation.Delving into the world of Pytorch, you’ve probably encountered an error termed as “Runtimeerror: Element 0 Of Tensors Does Not Require Grad And Does Not Have A Grad_Fn”. At first glance, it may seem baffling but by understanding some of the key contributors to this error, we can unravel ways to resolve and prevent it.
- Tensors and Gradients
Tensors are multidimensional arrays and are a central feature in Pytorch. The
requires_grad
attribute in Tensor objects indicates whether we need to compute gradients with respect to these tensors during backward passes. If the Tensor property `
requires_grad
` is False (which means it does not require computation of gradients), and yet we invoke operations on it that require gradient computation, we might encounter this infamous runtime error. As a general rule of thumb, always ensure the requires_grad setting aligns with your use case.
To illustrate my point, if you run the following code:
import torch
x = torch.tensor([1., 2., 3.])
y = x ** 2
y.backward()
This will raise a ‘RuntimeError’ because the tensor ‘x’ does not have `requires_grad=True`.
Now if you add `requires_grad=True`:
x = torch.tensor([1., 2., 3.], requires_grad=True)
y= x ** 2
y.backward()
And voila! The RuntimeError vanishes!
- The grad_fn None Error
In PyTorch, every variable has two properties – `
data
` and `
grad_fn
`. `
data
` refers to the data contained in the variable while `
grad_fn
` represents the function that generated this variable. If `
grad_fn
` is none (generally due to some operation that disconnects the tensor from its computational graph), running backpropagation methods like `backward()` would throw a similar ‘RuntimeError’.
Modifying our previously used code as:
x = torch.tensor([1., 2., 3.], requires_grad=True)
y = x.detach()**2
y.backward()
Here, using
detach()
method breaks the connection and hence causes the runtime error.
So to avoid this problem, remove any operations disconnecting the tensor from its computational graph.
- Casting Issues
Casting data from one form to another improperly could lead to this error. Suppose we cast a tensor that needs gradients (`requires_grad=True`) to numpy array and then attempted backward propagation. Since numpy doesn’t support automatic differentiation, Pytorch would be unable to determine ‘grad_fn’ and would prompt a ‘RuntimeError’.
Consider this example:
x = torch.tensor([1., 2., 3.], requires_grad=True)
y = np.power(x.numpy(), 2)
y.backward()
As correcting action, make sure you carry out differentiable operations within PyTorch framework itself and resist converting tensors to other forms prematurely.
These factors sums up the most common cases leading to ‘RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn’. By appropriately managing the requires_grad property, ensuring no disconnection of a tensor from its computational graph, and properly performing casting, we should be able to effectively steer clear of this pitfall. Remember to be attentive of these pitfalls when solving complex problems with Pytorch and happy coding!
Indeed, it’s a common query that revolves around the PyTorch framework – how to address `RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn` issue. This error usually indicates that one is trying to compute gradients via backpropagation on a tensor that doesn’t track history (In PyTorch, tensors have a Boolean field `requires_grad`. If `requires_grad=True`, then these tensor operations get tracked).
Firstly, let’s understand this problem analytically. The parameter tensors in PyTorch carry gradient information along with them. The `autograd` package in PyTorch implements gradient descent and backpropagation for all tensors with `requires_grad=True`. Now, when the error says “element 0 of tensors does not require grad and does not have a grad_fn”, it means you’re trying to calculate the gradients with respect to some part of your model graph that does not contain any trainable parameters.
Several practical solutions can be adopted to rectify this situation:
– **Ensure All Tensors Require Gradient**: You may want to ensure nodes-like tensors that provide input to your derivative operations always require a gradient.
tensor.requires_grad_()
By using `requires_grad_()` method, we can change the `requires_grad` attribute in place.
– **Use nn.Parameters:** We can use `nn.Parameter` to automatically set `requires_grad = True`.
param = torch.nn.Parameter(torch.rand(5, 7))
– **Place Variable Calculation Inside Training Loop:** Placing the calculations which involve variables requiring gradient inside the training loop.
– **Calculate Gradients Only On Leaf Tensors:** In PyTorch, only leaf tensors (tensors which have their `requires_grad` property set to `True` and are not the result of an operation) will have their gradients stored by calling the backward function.
Take a look at this snippet as an example. Here, “a” is a leaf tensor as it was created by us and its grad is available. However, “b” is made via an operation therefore results in having no grad.
a = torch.Tensor([2]) a.requires_grad = True b = a + 2 c = b.mean() c.backward() print(a.grad) # Output is tensor([1.]) print(b.grad) # Output is None since b is not a leaf tensor
There are also other smart ways to deal with this. For instance, calling Detach Method:
– **Calling Detach():** Using the `detach()` method to create a tensor that shares storage with the original tensor without tracking history.
a = torch.tensor([2.], requires_grad=True) b = a.detach() b.requires_grad = True
Pytorch follows a dynamic computational graph approach. So, the key point to remember here is that the computation graph needs to be recreated for every new batch, and adding operations outside the training loop could lead to tensors not requiring gradients. Make sure the operations you perform within the scope of the training loop if you need to compute gradients through them. Also revisiting the simple principle-anything you want derivatives should either be a leaf variable or something that has a chain of operations leading to a leaf variable-can help resolving this.
For detailed insights, you could refer to the official Pytorch Autograd Tutorial.Absolutely, understanding the role and importance of
grad_fn
in PyTorch contributes greatly to diagnosing issues like “RuntimeError: Element 0 of tensors does not require grad and does not have a grad_fn.”
PyTorch is an exquisite library for neural network-based machine learning. To peak under the hood of PyTorch’s power, we land right at two significant aspects: Automatic Differentiation and Computational Graphs.
grad_fn
relates to both these aspects, coming into play when you initialize a tensor that requires computation of gradients. You typically do this by setting
requires_grad=True
.
Here’s how it might look like:
import torch x = torch.randn(2, 2, requires_grad=True) y = x + 2
In this code, since `y` is created as a result of an operation (addition), it has a
grad_fn
attribute. You can see this if you print
y.grad_fn
.
The ‘grad’ in
grad_fn
stands for gradient, which refers to derivative calculations, while ‘fn’ represents function. In essence, PyTorch is tracking operations for tensors that are flagged with `requires_grad=True`.
So, why should this matter?
The importance of this ground-breaking Autograd engine resonates with the very heart of deep learning – back propagation! By keeping track of the computational graph history and providing automatic differentiation capabilities, PyTorch makes it possible to compute those crucial gradient descents for model training optimization.
Now, let’s address the RuntimeError you’re encountering. If you come across an error message mentioning missing
grad_fn
for an element of tensors, this essentially means PyTorch was instructed somewhere in the codebase to perform gradient calculations on a tensor that has not been assigned with
requires_grad=True
. Which essentially means, there will be no differential values calculated for a called upon backward pass during the training phase.
Understanding this mechanism helps rectify errors such as “RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn”. This specific error means that_grad method is called from a tensor that doesn’t have
grad_fn
. For instance, check this code:
t1 = torch.tensor([1.0, 2.0]) t1.backward()
This will throw the exact same runtime error because
t1
tensor was not initialized with
requires_grad=True
.
To prevent CNN models running into this snag, ensure that your tensors expected to partake in gradient computations are correctly initialized. Check if the
requires_grad
tag is set appropriately where needed. A keen eye cast over your tensors, losses, and parameters would go a long way towards error-free model training.
You may also find additional help navigating these PyTorch specifics within its elaborate [official documentation](https://pytorch.org/docs/stable/index.html) or authored guides spread out across major platforms like [StackOverflow](https://stackoverflow.com/questions/tagged/pytorch).
Lastly, remember, every
grad_fn
strongly corresponds to the tensor’s creation. So, appreciate it when debugging tensor operations within the Autograd system. It serves as a key to unlock the secret life of tensors and nurture a deeper understanding of optimizing loss functions during model training.When you are training a neural network model in PyTorch (Check out the official PyTorch documentation), the computation is directed by an internal mechanism known as the computational graph. The creation of this graph is driven by the `requires_grad` attribute. This property, when set to `True`, enables automatic differentiation and gradient computation for the tensor.
A common issue that many data science practitioners encounter during the model training phase is, a RuntimeError stating: ‘element 0 of tensors does not require grad and does not have a grad_fn’. This error simply communicates that one of your tensors does not have its `requires_grad` property enabled or set to true and hence PyTorch does not know how to compute gradients for it.
This dilemma can be vastly controlled using several approaches:
– First, there is the need to ensure that all parameters that should contribute to the computation of gradients have their `requires_grad` property set to `True` before commencing the backpropagation process. You can set the `requires_grad` attribute to `True` either when you create your tensors, or at any point in your program before the differentiation occurs.