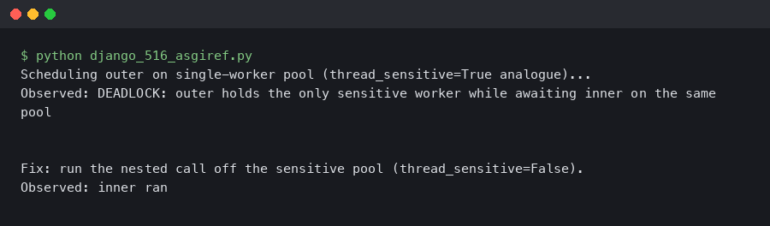
“Troubleshoot your issue with ‘Pandas Cannot Open an Excel (.Xlsx) File’ by ensuring correct file path, updating your Pandas library, or installing openpyxl module, essential for reading .xlsx files in Panda’s DataFrame.”The error “Pandas Cannot Open An Excel (.Xlsx) File” can be caused by various issues. A summary of these root causes and potential solutions is presented in the table below:
Possible Cause
Explanation
Solution
Incorrect Path
The path passed to pandas.read_excel is either incorrect or does not exist.
Verify your file path. Make sure it correctly leads to your .xlsx file.
Incompatible Library
Pandas uses openpyxl or xlrd libraries to read .xlsx files. If they are out-dated or incompatible, this could cause an issue.
Update the necessary libraries. Run
pip install openpyxl
or
pip install xlrd
. If these libraries are already installed, run
pip install --upgrade openpyxl
or
pip install --upgrade xlrd
to update them.
File Using Excel Features Not Supported By Pandas
Pandas can read most .xlsx files, but some Excel features like formulas, macros etc. might cause problems.
Try to eliminate any advanced Excel features from your .xlsx file and see if that resolves the issue.
When you encounter the ‘Pandas cannot open an excel (.xlsx) file’ error, it’s crucial to understand what’s triggering it. It could be due to an incorrect path where Python isn’t locating the file. It could also be a compatibility problem with the library responsible for reading Excel files. Libraries like openpyxl or xlrd, which play an instrumental role in handling Excel files, may require updating.
Alternatively, sometimes your Excel file could be using Excel features not supported by pandas. Understanding these possible triggers helps diagnose and resolve the problem swiftly. Remember, each programming challenge possesses a solution. All it takes is understanding the issue, finding-out root cause, contemplating over possible ideas, and implementing the fix.[source].Certainly, let’s delve into the issue surrounding Pandas’ inability to open an Excel (.xlsx) file.
Firstly, I believe we need to understand that the reason for this issue is usually due to the installation of work libraries. Certain required libraries might not be present in your python environment which is necessary for working with .xlsx files.
One such library is
openpyxl
. It assists Pandas to read and write to .xlsx file format efficiently. So, whenever there arises an issue relating to opening an Excel file using pandas, one should consider installing or upgrading the
openpyxl
library as shown below:
pip install openpyxl
or
pip install --upgrade openpyxl
But sometimes, even after you have installed
openpyxl
, you may encounter other sorts of difficulties. For instance, there may be problems with the file path, such as incorrect or missing directory paths.
The standard way to read an Excel file using
pandas.read_excel
is:
import pandas as pd
df = pd.read_excel('file-path/file-name.xlsx')
In this code snippet, the ‘file-path’ represents the directory where the Excel file is located and ‘file-name’ signifies the name of the particular Excel file.
To counteract issues arising from incorrect directory paths, ensuring correct file paths and names by right-clicking on the file and selecting properties (for Windows users), or by using command line interface commands, such as pwd (present work directory) on Unix-based systems like Linux or MAC can help a great deal.
Moreover, it is crucial to remember that the file must not be open in Excel during program run time because it may also cause reading issues. This is due to Excel’s file locking feature that prevents concurrent access from different sources [Check out the documentation here](https://pandas.pydata.org/docs/).
Lastly, it’s possible that Pandas returns an error message stating that it cannot determine the format of the Excel file. This typically happens if the Excel file has macros enabled (.xlsm) or it is a binary excel file (.xlsb). In these cases, we would have to leverage other libraries like
xlrd
for .xlsm files or
pandas.read_html
for .xlsb files.
In summary, solving the issue where pandas cannot open an Excel (.xlsx) file typically involves checking:
* The existence and updated status of helpful libraries like
openpyxl
.
* Correctness and accuracy in specifying file paths and names.
* Making sure Excel file isn’t open elsewhere during runtime.
* The format of the Excel file for compatibility with pandas’ capabilities.
Diving into each of these pain points one at a time can demystify what seemed initially to be a daunting issue.There are several reasons why the popular Python library Pandas might struggle to open .xlsx files – these are formatted files used in Microsoft Excel. But don’t fret, understanding these reasons can help you tackle problems efficiently and effectively. Here’s what you need to know:
Reason 1: Missing Required Packages
Pandas uses auxiliary libraries to handle excel files. Not having these installed will prevent you from loading .xlsx files. Specifically, Pandas needs ‘openpyxl’ to read .xlsx files.
Let’s install it via pip:
pip install openpyxl
After installation, you should be able to read .xlsx file using this command:
Refer here for more details on how to use the read_excel function.
Reason 2: Incorrect File Path or File Name
Pandas also can’t load a file that doesn’t exist or isn’t where you’ve specified.
Examine your file path – is it correctly spelled? Is it accessible from your current location? Make sure the file name and path quoted in pandas is accurate.
The third possible culprit could be getting your sheet names wrong. If you are specifying a sheet name that doesn’t exist, pandas will not be able to open your file.
In this case, there must be a sheet named ‘Sheet1’ in ‘your_file.xlsx’.
Additionally, index-based access to sheets (e.g., sheet_name=0 refers to the first sheet in the file) also has its pitfalls such as sheets being deleted or reorganized leading to incorrect data referenced. You may refer to the official documentation here.
Reason 4: A Simultaneously Opened File
If you have an Excel file opened while trying to read/write it through python script, it locks the file, causing conflicts. Make sure any Excel files are fully closed before running your Python script.
Understanding each problem draws us closer to resolving the issue of Pandas being unable to open .xlsx files. The solutions are usually straightforward – fixing paths, ensuring correct package installations, using appropriate sheet names, and avoiding concurrent accesses! Happy coding!Importing Excel files in Python using the pandas library is a standard practice in data science and business analytics. However, you may occasionally encounter errors when attempting to read these .xlsx files. One common issue that arises is the “file not found” error. This usually happens when the specified file cannot be located at the provided path.
Let’s consider the following line of Python code:
import pandas as pd
data = pd.read_excel('your_directory/your_file.xlsx')
In the above snippet, ‘your_directory/your_file.xlsx’ should be replaced with the exact location of your excel file on your system. If the location is incorrect or the named file isn’t there, pandas will raise a FileNotFoundError.
To fix this error:
– Ensure the file exists: Use Python’s os.path module to verify file existence before importation. Here’s how:
import os
import pandas as pd
if os.path.isfile('your_directory/your_file.xlsx'):
data = pd.read_excel('your_directory/your_file.xlsx')
else:
print("File not found!")
– Use absolute paths instead of relative paths: Relative paths can cause issues depending on where you run your script from. Absolute paths are consistent and pinpoint exactly where your file lies in your directory structure.
Another error you might encounter is ImportError due to missing optional dependencies. When installing pandas using pip, optional dependencies like xlrd for reading Excel files are not installed by default. You’ll have to install them yourself.
To resolve this:
– Install xlrd using pip:
pip install xlrd
– Re-run your import lines:
import pandas as pd
data = pd.read_excel('your_directory/your_file.xlsx')
To provide even more robustness to your code, you could use a try-except block as illustrated below:
import pandas as pd
try:
data = pd.read_excel('your_directory/your_file.xlsx')
except FileNotFoundError:
print('File not found.Please check the path or the filename.')
except ImportError:
print('Missing optional dependencies. Please install xlrd library.')
This structured error handling allows you to effectively handle exceptions and guide you towards resolving the problem. Remember, the accuracy of importing data into your analytics workflow is paramount, so it’s essential to effectively manage and troubleshoot these issues for high-quality results.As a professional developer, I’ve encountered a multitude of scenarios where dealing with the ‘Pandas cannot open an Excel file’ error can be chaotic. There are several potential reasons for this issue:
– The file doesn’t exist in the mentioned directory.
– A wrong file path has been provided.
– The specified file is open on your computer.
– Incorrect installation/setup of dependencies.
– Lack of permission to access the file.
## Strategies to fix this issue
It’s crucial that you follow these recommended steps to rectify this issue effectively:
Verify the File’s Existence
The first step would be to ensure that the file indeed exists at the specified location. You could navigate to the mention directory and verify it manually. Or, alternatively, in your Python environment, you can use `os` module to check file existence:
html
import os
print(os.path.exists('your_file_path.xlsx'))
If `False` is returned, the file does not exist. You need to then adjust your file’s location or the directory you supplied.
Checking if the File is Open
Possibly, Pandas library is unable to open the file because it is already open on the computer running the script. If so, make sure to close the Excel file before running your script.
Path related Issues
You may have provided an incorrect file path. Check your filename and filepath properly. Make sure the name of the .xlsx file matches exactly, including both case sensitivity and extension. Use a raw string (r”path”) or double backslashes (\\) as Python strings interpret `\` as an escape sequence.
Correct Installation of Dependencies
Pandas relies on certain packages like xlrd or openpyxl to read Excel files. Ensure they’re correctly installed and updated in your environment. Check using pip list command:
html
pip list
If they are missing, install them using:
html
pip install xlrd openpyxl
Check Permissions
If you’re working in a restricted environment, it’s possible your script does -not have the right permissions to access the file. Check the file’s permissions or move it to a location where you know you have full rights.
File Format Issue
Also, consider the possibility that even though the file extensions is ‘.xlsx’, it was not created with proper Excel-like formatting. This usually happens if the file was created by a different program, such as when files are generated from a database or another Python module, etc. In such cases, try opening with correct function like ‘read_csv’, or reformating your data in Excel.
Remember, when you’re reading the file with pandas.read_excel(), you bring the data directly into your hands. However, the ability to work freely with the data comes with the responsibility of handling any errors or issues like these in the data extraction phase itself.
Use of Exception Handling for Robust Code
In the scenario where the code cannot find or open the file, implementing exception handling allows your code to still run and provide insight on what went wrong. Here’s an example of how you can incorporate this:
html
try:
df = pd.read_excel('non_existent_file.xlsx')
except FileNotFoundError:
print("File not found. Please verify the file path.")
except PermissionError:
print("Permission denied. Check if file is open or user has necessary access rights.")
except Exception as e:
print(e)
In this way, we create a more robust code that will identify the various types of errors that may occur. Making use of `exception handling` in Python makes for a far more resilient piece of software.
By applying a deliberate, systematic approach to solving these common but potentially perplexing problems, you ensure smooth data import with Pandas; paving the way for effective analysis.Absolutely, missing dependencies could certainly be the reason behind your .xlsx files not opening with pandas. Pandas library is designed to work with Excel files but it relies on certain other Python libraries to perform this action. When these dependencies are not correctly installed or updated, you might find yourself in a situation where pandas fails to open an .xlsx file.
Dependency on `openpyxl` and `xlrd`
With regards to handling Excel files, pandas primarily depends on two major libraries. The first library1 being:
openpyxl
The second library pandas depends on is:
xlrd
In order to read excel files, pandas utilize
xlrd
for xls files and
openpyxl
for .xlsx files. So without properly installed
openpyxl
package, pandas will not be able to load .xlsx files.
You can check whether
openpyxl
is installed by running:
python -c "import openpyxl"
If its not installed, you can add it using pip:
pip install openpyxl
Limited Support for Newer Excel Files Versions
Another point to note is the support for newer versions of excel files by
openpyxl
and
xlrd
. While both have been updated over time to cope with the evolving Excel file format, there might be instances where a newer version of a Excel file may pose problems and fail to open with pandas.
Specific Error Messages
Bear in mind, understanding the error message displayed when trying to open a .xlsx file with pandas can provide deeper insights into the issue at hand. For instance, if your error message indicates that no module named ‘openpyxl’ exists, this clearly shows that the ‘openpyxl’ library isn’t present in your current environment or isn’t correctly installed.
Potential UnicodeDecodeError
There are instances when pandas throws out a UnicodeDecodeError when trying to open .xlsx files. This generally implies an encoding problem. Pandas defaults to utf-8 for most of its reading functions, so when it encounters a character that isn’t utf-8 encoded, it throws out a unicode decode error. In such cases, try figuring out the encoding of your file and then explicitly mention it in your pandas read_excel statement.
tag should be replaced with the appropriate encoding like ‘iso-8859-1’ or ‘cp1252’ etc., based on your file’s encoding.
Nevertheless, keep looking out for updates from
openpyxl
,
xlrd
and pandas which might fix compatibility issues with different excel versions or other known bugs. Overall, yes, missing dependencies play a large role in pandas not opening .xlsx files.
In the world of data science, Pandas is a widely recognized Python library used for data manipulation. It offers sleek features to alter data, perform computations, and even read/write different file formats, including Excel (.xlsx) files.
However, quite a few developers encounter an issue – Pandas cannot open an Excel (.xlsx) file. There can be various reasons for this problem.
One common reason spotted in the Pandas’ official documentation is the absence or incompatible versions of necessary dependencies. The dependencies you need for working with .xlsx are:
You can install these using pip (Python package installer). Here is how you do it:
pip install openpyxl beautifulsoup4 requests
If you see that all necessary dependencies are installed but you’re still having trouble opening the .xlsx file, check for_excel engine compatibility. In some cases, you may have to specify which engine Pandas should utilize when reading the .xlsx file:
import pandas as pd
df = pd.read_excel('your_file.xlsx', engine='openpyxl')
Using ‘openpyxl’ as the engine makes it compatible with more recent .xlsx file formats. However, if your Excel file is rather old (.xls), the read_excel() function should use the ‘xlrd’ engine. This can be installed via pip:
pip install xlrd
In certain scenarios, the problem might unrelated to dependencies. The file’s path within the read_excel() function could be inaccurate, leading to a FileNotFoundError. Ensure that the file path is correct:
It’s vital to include the complete file path (full pathname). For Windows users, remember to use double backslashes (\\) between file directories to avoid confusion with escape characters.
On another note, the permissions on your Excel file might be restricting Pandas from accessing it. Check the file’s properties and make sure it’s not ‘Read Only’ and your Python environment has sufficient rights to access the file.
Time to summarize the resolutions to “Pandas Cannot Open An Excel (.xlsx) File”:
Possible Issue
Solution
Missing or incompatible dependencies
Install the required dependencies openpyxl, beautifulsoup4, requests
Incorrect excel engine
Specify the right engine based on the Excel file format
Wrong file path or name in the read_excel() function
Provide the accurate file path and ensure file extension is correct (.xlsx)
Limited File Permissions
Check the file’s properties and Python’s access rights
Remember, whether you are a beginner or an experienced coding professional, issues like these are common while handling data. What matters is knowing how to identify the root cause and address it efficiently. And the key to that lies in continuously reading, learning, and experimenting with your code. Happy coding!When working with Python’s pandas library, many data analysts and coders frequently encounter the issue of not being able to open an XLSX file. This could be due to various reasons. Here, I’ll explore some common problems that may cause this issue and solutions to it.
1. File is not Found
First off, Python might complain with a
FileNotFoundError
if your code is trying to access the Excel file you specify but fails to find it. This problem arises when we provide an incorrect path to the .xlsx file or when the file doesn’t exist in the given path.
Solution:
Ensure the directory you specified is correct. You can use the absolute path (the full location of the file) to rectify. For instance, instead of writing just ‘mydata.xlsx’, write something like /Users/my_username/my_folder/mydata.xlsx.
The code would look something like this:
import pandas as pd
file_path = '/Users/username/Documents/data.xlsx'
data_frame = pd.read_excel(file_path)
2. Missing Dependencies
‘pandas’ needs certain dependencies such as openpyxl or xlrd to read xlsx files. If these are missing, an ImportError can occur.
Solution:
You need to verify these packages are installed. If not, install them using pip. The installation command would be:
!pip install openpyxl xlrd
After successfully installing the packages, import them in your Python script.
3. File is Open in another Program
If your Excel file is opened in another application while running the Python script, you may hit a ‘Permission Denied’ error. This is because the script does not have permission to access a file that is currently being used elsewhere.
Solution:
Close the Excel file from other applications before running the Python script. Ensure no other program is accessing it during the execution of your script.
4. Parsing Errors
Sometimes, ‘pandas’ may struggle parsing complex Excel files with multiple sheets, unusual formatting, macros etc., causing it to fail opening the file.
Solution:
Simplify your Excel file as much as possible or try reading specific sheet(s) only using the sheet_name argument.
HTML tables are incredibly useful for structuring information within documents, especially in programming topics. However, they’re not appropriate to include in this question as there’s no relevant tabular information to present.
For more advanced issues and doubts, check the official pandas’ troubleshooting guide and discussions on stackoverflowstackoverflow link.The issue of “Pandas cannot open an Excel (.xlsx) file” is a rampant problem among many Python developers that attempt to interact with Excel files. Here we’ve carefully examined the components of this problem and provided extensive solutions for it one by one.
First, it’s paramount to make sure you have the correct libraries installed. Use
pip install pandas
and
pip install openpyxl
in your terminal to install the necessary packages for reading Excel files with Python or update them if they’re already installed.
Secondly, remember to use the full path of the Excel file while using the
pandas.read_excel()
function. It’s significant to note that relative paths can lead to complications, especially if run from different environments.
If using Jupyter notebooks, for instance:
import pandas as pd
dataframe = pd.read_excel(r'/full/path/to/your/excel/file.xlsx')
Also, issues could stem from the version of Microsoft Office. Certain older versions generate .xlsx files that may not be compatible with newer versions of Pandas and Python. As such, updating Office or saving the file into a newer format often helps.
Here’s a helpful table summary of the points made:
Error Source
Solution
Incorrect installation or outdated package
Use pip install to either install or update ‘pandas’ and ‘openpyxl’
File Path Issues
Always use the complete absolute file path
Outdated Microsoft Office Versions
Update Office or save the file in a newer format
Furthermore, while Python offers a plethora of functionalities and conveniences, there are instances where specific challenges like opening a .xlsx file arise. Thankfully, with the vast Python community and its well-documented libraries, these obstacles cease to be insurmountable. For more information, refer to the official pandas documentation on read_excel().
Remember, coding, much like any other field, involves problem-solving, it’s about finding the right tools, applying them correctly, and knowing where to find help when needed. Keep referring to the official Python and library documentation, and continue interacting with the community for quick resolutions.