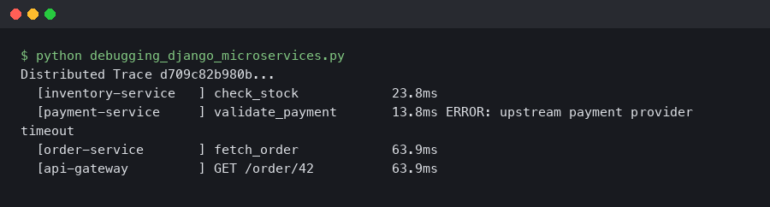
Actually, I should clarify – I spent last Tuesday night staring at a terminal window, waiting for a traceback that never came. My AI agent—a supposedly “smart” customer support bot running on GPT-4o—had just hallucinated a refund policy that doesn’t exist, promised a customer $500 in credit, and then politely closed the ticket.
The Python logs? Clean.
The HTTP status codes? 200 OK across the board.
The standard observability tools? Useless.
But when an LLM fails, it doesn’t crash. It drifts. It confidently walks off a cliff while smiling.
After that $500 incident (which I caught before the API call actually fired, thank god), I stopped trying to debug agents like they were standard Python scripts. I realized I needed a “Flight Recorder.” A way to reconstruct the cognitive stack trace of the model, not just the execution stack of the runtime.
The “Why” is Missing
Standard logging tells you what happened. “Function call_refund_tool executed.” Great. But why did the agent think that was the right move?
I built a lightweight system to capture this. No heavy SaaS integrations, just a local SQLite file. Why SQLite? Because I can query it with SQL, it’s fast, and I don’t need an internet connection to debug my local dev environment.
Building the Flight Recorder
The goal is to log the “Cognitive Frame” of every step. A standard stack trace is a snapshot of memory. A cognitive stack trace is a snapshot of context.
import sqlite3
import json
from datetime import datetime
from typing import Any, Dict, Optional
class FlightRecorder:
def __init__(self, db_path: str = "agent_trace.db"):
self.conn = sqlite3.connect(db_path)
self.cursor = self.conn.cursor()
self._init_db()
def _init_db(self):
# We're logging the 'thought process', not just the error
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS trace_log (
id INTEGER PRIMARY KEY AUTOINCREMENT,
run_id TEXT,
step_number INTEGER,
timestamp DATETIME,
intent TEXT, -- What the agent WANTED to do
tool_call TEXT, -- The actual function called
tool_output TEXT, -- What the world sent back
policy_verdict TEXT, -- Did it pass guardrails?
violation_reason TEXT, -- If it failed, why?
full_context JSON -- The expensive part: full prompt state
)
""")
self.conn.commit()
def log_step(self,
run_id: str,
step: int,
intent: str,
tool: str,
output: Any,
verdict: str = "PASS",
violation: Optional[str] = None):
self.cursor.execute("""
INSERT INTO trace_log
(run_id, step_number, timestamp, intent, tool_call, tool_output, policy_verdict, violation_reason)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
run_id,
step,
datetime.now(),
intent,
tool,
json.dumps(output),
verdict,
violation
))
self.conn.commit()
def query_crash(self, run_id: str):
# This is the "Stack Trace" view
print(f"--- INVESTIGATION FOR RUN {run_id} ---")
rows = self.cursor.execute(
"SELECT step_number, intent, policy_verdict, violation_reason FROM trace_log WHERE run_id = ? ORDER BY step_number",
(run_id,)
).fetchall()
for row in rows:
step, intent, verdict, reason = row
status = "🔴" if verdict == "FAIL" else "🟢"
print(f"{step}. {status} [{verdict}] Intent: {intent}")
if reason:
print(f" ERROR: {reason}")The “Aha” Moment
The very next day, I had a regression. The agent started failing to look up order history. Instead, I just ran a SQL query:
SELECT intent, tool_call, tool_output
FROM trace_log
WHERE policy_verdict = 'FAIL'
ORDER BY timestamp DESC LIMIT 5;The result was immediate. The intent column showed: “User wants order status. Searching for order #12345.”
But the tool_call column showed: search_orders(query="12345").
The tool_output was: [] (Empty list).
That is the stack trace. Not a line number error, but a logic gap between “Expectation” (fuzzy search exists) and “Reality” (exact match only).

The Storage Trade-off (A Real-World Gotcha)
Do not log the full context window by default.
I also added a simple retention policy—a cron job that runs every Sunday at 3 AM to vacuum the DB and delete rows older than 7 days.
Why This Matters Now

Governance isn’t just a corporate buzzword; it’s about knowing why your code did something. If your agent violates a policy—like suggesting a competitor’s product or being rude—you need to point to the exact logic step where the guardrail failed.
Without a flight recorder, you’re just guessing. You’re tweaking the prompt, re-running, and hoping. That’s not engineering; that’s superstition.
So, stop relying on stdout. Build a table. Log the intent. Query the crash. It’s the only way to stay sane.
How do you debug an AI agent that hallucinates without throwing an error?
Because LLM agents drift rather than crash, standard Python tracebacks and HTTP status codes stay clean even when the logic fails. The article recommends building a Flight Recorder that captures the agent’s cognitive frame at each step, logging intent, tool calls, outputs, and guardrail verdicts to SQLite so you can reconstruct why the model made a decision, not just what executed.
Why use SQLite instead of a SaaS observability tool for agent logging?
SQLite is queryable with standard SQL, fast, and requires no internet connection, making it ideal for debugging a local development environment. The author chose it over heavy SaaS integrations because a lightweight local file lets you investigate agent behavior immediately without external dependencies or cost, while still supporting structured queries against intent, tool calls, and policy verdicts.
What columns should an agent trace log table contain?
The article’s trace_log schema includes run_id, step_number, timestamp, intent (what the agent wanted to do), tool_call (the function actually invoked), tool_output (the response), policy_verdict (whether it passed guardrails), violation_reason (why it failed), and full_context as JSON. Together these capture the cognitive frame of each step rather than just execution state.
How do you prevent an agent trace SQLite database from growing too large?
Do not log the full context window by default, since prompt state is the expensive part to store. The author added a retention policy implemented as a cron job that runs every Sunday at 3 AM to vacuum the database and delete rows older than seven days, keeping the trace file small enough for fast local queries.
Frequently asked questions
How do you debug an AI agent that hallucinates without throwing an error?
Because LLM agents drift rather than crash, standard Python tracebacks and HTTP status codes stay clean even when the logic fails. Build a Flight Recorder that captures the agent’s cognitive frame at each step, logging intent, tool calls, outputs, and guardrail verdicts to SQLite. This lets you reconstruct why the model made a decision, not just what executed, turning invisible logic drift into queryable evidence.
Why use SQLite instead of a SaaS observability tool for agent logging?
SQLite is queryable with standard SQL, fast, and requires no internet connection, making it ideal for debugging a local development environment. The author chose it over heavy SaaS integrations because a lightweight local file lets you investigate agent behavior immediately without external dependencies or subscription cost, while still supporting structured queries against intent, tool calls, and policy verdicts.
What columns should an agent trace log table contain?
The trace_log schema includes run_id, step_number, timestamp, intent (what the agent wanted to do), tool_call (the function actually invoked), tool_output (the response), policy_verdict (whether it passed guardrails), violation_reason (why it failed), and full_context stored as JSON. Together these fields capture the cognitive frame of each step rather than just execution state, making post-hoc investigation possible.
How do you prevent an agent trace SQLite database from growing too large?
Do not log the full context window by default, since prompt state is the expensive part to store. The author added a retention policy implemented as a cron job that runs every Sunday at 3 AM to vacuum the database and delete rows older than seven days, keeping the trace file small enough for fast local SQL queries during debugging sessions.