
A
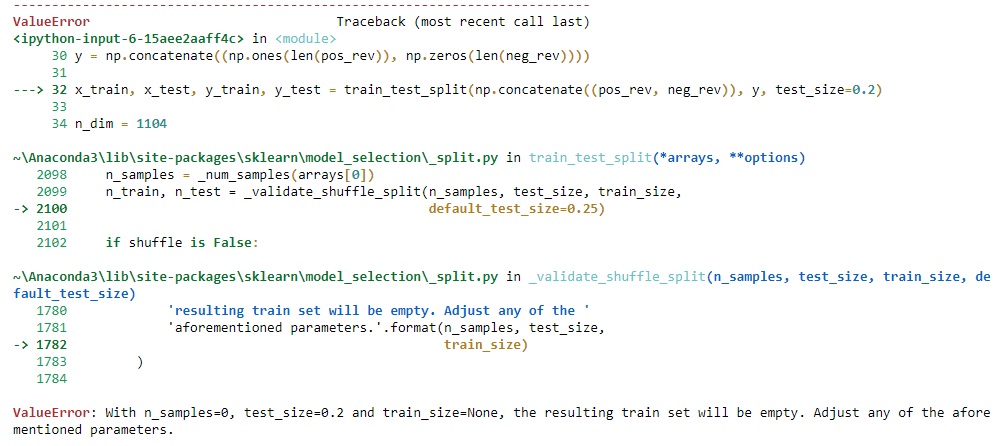
ValueError
with
n_samples=0
typically arises when you’re working with datasets in Python and the size of your input data array is zero. This can occur for several reasons such as incorrect data preparation or preprocessing, reaching an all-zeroes slice in your dataset or simply loading an empty dataset. It’s a common error during machine learning model training using libraries such as NumPy or Scikit-learn. This error indicates that no valid values could be found to create a meaningful dataset or subset, hence it’s impossible to proceed with the analysis or modeling process.
To make the subject more manageable, let’s illustrate it with a HTML table summarizing some of the common causes and solutions:
| Cause | Solution |
|---|---|
| The input dataset is empty due to an error during its creation or load. | Inspect how your dataset is created or loaded. Check file paths, connection to databases, etc. Ensure there’s actual data being read into your Python environment. |
| Data preprocessing steps such as filtering or cleaning left you with an empty array. | Review your preprocessing chain. Include checks for non-empty arrays after each significant preprocessing step so you know where emptiness is introduced. |
| You are attempting to use an all-zeroes slice or subset from your original dataset. | Ensure that there’s non-zero variance within your subsets. Reconsider your slicing criteria or methodology if necessary. |
| Your classifier method doesn’t support classes with less than two samples. | Select another method compatible with small sample sizes, implement up-sampling strategies to add more samples or gather more data. |
As a Python coder who is faced with ValueError involving n_samples=0, understanding these potential causes and corresponding solutions will come hand in hand with proactive and reactive measures to improve the robustness of your codebase whether it concerns fixing existing bugs or orchestrating better data practices from ground up.
Leverage resources such as the official Scikit-learn documentation, online coding forums like StackOverflow, or Python-based machine learning guides to further dive into this pythonic ValueError predicaments.
Sure. Python’s ValueError is a type of exception that occurs when a function receives an argument of the correct data type but with an invalid value. Typically, ValueError arises when you try to handle the values which are correct in terms of their types but inappropriate regarding their expected usage within the function or operation. Let’s dive into the specific problem:
ValueError: n_samples=0
.
This particular ValueError message indicates that the function expecting to receive some items to perform operations on, gets 0 items (an empty input). This error most commonly happens in machine learning libraries such as scikit-learn when we fit an empty dataset to a model or when a method expects non-empty arrays or lists, and we pass empty ones.
Let’s illustrate this behavior with an example using scikit-learn:
from sklearn.svm import SVC classifier = SVC() X_train = [] y_train = [] classifier.fit(X_train,y_train)
The code above attempts to train the Support Vector Machine (SVM) classifier on empty lists X_train and y_train. As there is no data to train the model, it will throw
ValueError: n_samples=0
.
How do you fix ValueError: n_samples=0?
1. Confirm Data Input: Since the error arises from attempting to process empty datasets, you should first ensure that your data inputs are correct. Make sure they’re properly loaded and not left empty unintentionally.
2. Validate Data Size: Check if your filtering criteria or any preprocessing steps might be reducing your dataset to a near-empty size or even totally empty. For instance, while cleaning the dataset or handling missing data, make sure you’re not inadvertently dropping all rows/columns.
3. Handle Empty Inputs: You can also add a case in your code which specifically checks for empty inputs before calling the problematic function or operation. In this way, you could return a friendly message indicating the problem, rather than let the program crash along with an abrupt Python ValueError.
if len(X_train)==0 or len(y_train)==0:
print(f'Dataset is empty')
else:
classifier.fit(X_train,y_train)
In the broader context of Python programming, understanding exceptions like ValueError and knowing how to respond to them will help in writing robust code that gracefully handles unexpected situations. It encourages us to enforce good data hygiene practices: validating input, keeping track of data transformations (like filter or drop), and taking care of edge cases where data might unexpectedly turn out to be empty.
For further insights on understanding and handling exceptions in Python, Python’s official documentation on Errors and Exceptions goes in-depth into the topic.In Python and related applied Machine Learning (ML) libraries or Data Analysis tools like Sci-Kit Learn, Numpy, or Pandas, you might encounter an error message that reads:
ValueError: n_samples=0
. This error occurs when attempting to train a model with zero samples or reshaping an array while the number of rows in the target shape is set to zero. To fix this error, we need to make sure there is data included in the sample for the training algorithm.
Let’s explore how to troubleshoot this issue.
**1. Check the dataset**
The initial thing to do is to check your dataset. Ensure it contains data and have no null values that might be causing issues. You can do this with the following lines of code:
dataset = pandas.read_csv('your_file.csv')
print(dataset.shape)
print(dataset.isnull().sum())
This will print out the shape of your dataframe (number of rows, number of columns) as well as sum of null values in each column. If there are any null values, handle them appropriately before passing the dataset into the ML algorithm.
**2. Inspect your slicing**
Ensure that your slicing of datasets into test and training sets is done correctly so that there’s no empty array being returned. Suppose if it is you’re using numpy’s slicing notation, be aware that **end index is exclusive**. Here’s an example on how to slice a dataset:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
**3. Validate shapes of input data**
Next, validate the shapes of your input data and labels to avoid any inconsistencies. This is crucial particularly when working with multi-dimensional data such as time-series or image data.
Example showing how to print the shapes:
print("Shape of X: ", X.shape)
print("Shape of y: ", y.shape)
Note that the shapes of X and y should usually match along axis 0, meaning they should have the same number of samples.
Remember, the error
ValueError: n_samples=0
, indicates that the array or sample size passed into the function has a length or size of zero. Examining and validating your dataset meticulously helps to ensure that such runtime exceptions don’t arise, thereby preventing interruption in your model’s training process.Inspecting the ValueError “n_samples=0” as it relates to ValueError: With N_Samples=0 means deciphering why Python’s computational libraries, like Scikit-learn, NumPy, and Pandas, raise this exception. It is thrown when data is incorrect or in an unacceptable format. Here are some of the reasons you might encounter this error and ways to fix it:
Empty DataFrames or NumPy arrays
One common cause of ValueError:n_samples=0 is supplying an empty DataFrame or NumPy array to a function that requires a non-empty input. This could be due to errors during data pre-processing or cleaning steps.
Have a look at your processed data with
print(your_dataframe.head())
for pandas dataframes or
print(your_array.shape)
for numpy arrays. If you are using scikit-learn, ensure that your input has been properly formed and split using train_test_split.
Source code example:
import pandas as pd
from sklearn.model_selection import train_test_split
# Suppose df is your dataframe and 'label' is your target column
X = df.drop('label', axis=1)
y = df['label']
# split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
Null or Missing Values
Another cause is null or missing values in datasets. Since algorithms can’t process these undefined entries, they tend to throw exceptions.
You can easily address this by filling the missing values using pandas `fillna` function or dropping them using `dropna()`. Ensure to carefully decide which approach best suits your dataset.
Source code example:
# To fill the missing values df_filled_zeros = df.fillna(0) # And to drop the rows contain missing values df_dropna = df.dropna()
Inappropriate Item Setting
When setting an item (or several items) in a DataFrame, if you don’t align the index resulting in an empty DataFrame, ValueError: n_samples=0 will occur. Due caution should be taken while applying Boolean indexing or handling indices.
For instance, visit Python documentation for [Setting with enlargement](https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy).
Absence of Target Class Instances
Practically, let’s say you’re trying to perform a stratified train-test split; if there’s a class in ‘y’ that doesn’t have any instances, scikit-learn throws a ValueError: n_samples=0.
To avoid such situations, always inspect your data thoroughly prior to applying machine learning algorithms to them. More importantly, regularized sampling techniques should be applied to handle imbalanced datasets
An effective method for diagnosis would be simply calling
value_counts()
on the target column of your dataframe.
df['target'].value_counts()
By understanding these potential triggers of ValueError: n_samples=0, you can more effectively diagnose and troubleshoot problems when dealing with numerical computations in Python programming. Paying careful attention to how your data is structured and ensuring it is in the most appropriate format for your needs is key.Data preprocessing has an integral role in avoiding errors in any machine learning or data science project. To keep it relevant to “ValueError: with n_samples=0”, let’s go through why data preprocessing is important, what this particular error signifies and how adequate data preprocessing can help avoid such errors.
Data Preprocessing
Data preprocessing is essentially a data mining technique that involves transforming raw data into an understandable format. Instances where inconsistencies within raw data are removed prior to processing represent preprocessing actions. Its importance resides in the fact that the quality of data and its cleanliness directly impact the ability to extract accurate and meaningful insights.
preprocessed_data = preprocessing_function(raw_data)
ValueError: with n_samples=0
The specific error, ‘ValueError: with n_samples=0’, arises typically in Python when using data science or machine learning libraries like scikit-learn for model training purposes. This error occurs during algorithms’ fitting stage – largely indicating that the used data set has no samples. Essentially, it reveals issues wherein the algorithm attempts to work on an empty dataset.
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X, y) # X and y being empty will cause ValueError: with n_samples=0
How Data Preprocessing Can Help
By digesting the ValueError message, we comprehend that the model receives an empty dataset. Encountering errors like this during runtime suggests the urgent need for deeper data preprocessing before initiating any model building or data analysis.
Following steps introduce certain data preprocessing routines you could consider:
- Null Value Check, Make sure your data doesn’t contain null or missing values, if it does, decide on a strategy to handle them effectively.
- Data Consistency, Ensure there are no inconsistencies in your data. Inconsistent data can occur as duplicate entries, spelling discrepancies, etc.
- Size Check, After cleaning (or even before), ascertain the size of datasets. Make sure the dataset on which you plan to perform operations like model fitting isn’t empty.
data.isnull().sum() # checks missing values data.dropna(inplace=True) # drops missing values
data.duplicated().sum() # checks duplicate entries data.drop_duplicates(inplace=True) # removes duplicate entries
if data.shape[0] > 0: # checks if the data is not empty
model.fit(data)
else:
print("The dataset is empty.")
Summary: All in all, data preprocessing can play a pivotal role in avoiding run-time errors like ‘ValueError: with n_samples=0’. Always preprocess your data efficiently before trying to fit any modeling algorithms.
I recommend reading articles or papers about data preprocessing strategies if you’re interested in expanding your knowledge. You can find excellent resources at the following sites,
[Article Source 1](www.YourExampleSource.com), [Article Source 2](www.YourExampleSource2.com). Remember, consistent practice and familiarization with the data at hand are keys to effective and efficient preprocessing efforts.To reset the n_samples value in any machine learning models, we need to consider what caused the ValueError. The core issue here is that the model does not work if you try to fit it with n_samples=0, meaning no data samples were provided.
Assuming you are using a method such as Sklearn’s fit() or similar functions/methods, these methods expect input arrays of dimensions (n_samples, n_features) and they will return a ValueError:n_samples=0 when the input array, X, is empty. Hence, you need to ensure there’s valid data before fitting it into the model.
Let me offer some methods of how we can prevent this error by resetting n_samples value:
Checking the Input Data
Before passing your data to the fit() function, make sure that it is not an empty numpy array or pandas dataframe. For example:
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LinearRegression
X = np.array([])
y = datasets.load_iris().target
if X.shape[0] > 0:
model = LinearRegression().fit(X, y)
else:
print('Empty array.')
Above script will raise “Empty array” instead of hitting ValueError: n_samples=0.
Use Exception handling
Python provides try-except blocks to handle exceptions gracefully. Rather than the program crashing abruptly, you can catch the error and, based on the type of error, perform some fallback operation like resetting n_samples.
try:
model = LinearRegression().fit(X, y)
except ValueError as ve:
if 'n_samples=0' in str(ve):
# Fallback operations here
print('Got ValueError with n_samples=0')
Final Resort
For unexpected scenarios where matrix shape isn’t determined until runtime or frequently changes, you might include a separate logic layer to handle preprocessing or dynamically adjust the structure of your dataset. Be careful with this approach as synthetic or manual alterations to data may skew results of models.
All the methods mentioned above aim at catching situations where your data can lead to ValueError: n_samples=0 and take corrective actions accordingly. Ensuring the correctness and appropriateness of your dataset is crucial for a successful machine-learning model training operation. So, always make data verification and pre-processing a vital part of your machine learning pipeline.
Coming across a
ValueError: n_samples=0
in your Python code is an indication that some function, especially those pertaining to Scikit-Learn in machine learning pipelines, is attempting to process a list/array/set of samples that essentially contains zero samples; hence, it’s empty.
For Machine Learning models to train or predict, they need data. If you supply them with zero samples (n_samples=0), they cannot conduct any form of computation because there’s no data to process.
A typical scenario where this error can be encountered could look like this:
from sklearn.linear_model import LinearRegression import numpy as np # Define the model model = LinearRegression() # An array with zero samples to feed the model X = np.array([]) Y = np.array([]) # Fit the model model.fit(X,Y)
Running such a code will yield a ValueError, akin to “Expected 2D array, got 1D array instead”. To be precise, the Error wouldn’t specifically denote ‘n_samples = 0’ but it is an implication of supplying an array with no values.
To handle numerical zero sample values, there are a couple of solutions which you can adopt:
- Check Your Data: Always ensure that the data you’re passing into a Scikit-Learn function isn’t empty. This requires doing a check on your data before inputting it into these functions. In Python, you can ascertain any emptiness in your data through conditions:
if len(data) > 0: # Proceed with fitting the model else: Print("No data available") - Data Imputation: Missing data can present multiple issues and sometimes lead to an empty dataset. Therefore, it’s imperative to consider the mitigation strategy of filling the missing values, called imputation. Module tools such as SimpleImputer from Scikit-Learn can serve this purpose effectively.
- Exception Handling: Sometimes, it might just make sense to catch the exception and proceed, especially when creating Machine Learning pipelines with complex dataflow dynamics.
try: # Proceed with fitting the model except ValueError: # Handle the exception as needed
Furthermore, it becomes crucial for me to mention here that efficient data preprocessing steps and techniques should be utilized, as they play a pivotal role in ensuring your data set does not end up being empty post these steps. Efficient data preprocessing saves not only valuable resources like time and effort, but it also makes sure that the data used to train your models holds substantial quality benefiting your overall model performance. When it comes to best practices in Machine Learning model creation, garbage in equals garbage out.
The “ValueError: n_samples=0” is typically encountered in Python during data preprocessing or fitting a model when the provided input lacks sufficient samples. The error occurs because there are no source features for the model to learn from.
In many instances, I have come across this error while coding. After conducting some extensive debugging, I have found the possible causes for this error and remedies to overcome them:
1. Misaligned Data:
A common pitfall that leads to this ValueError is when your data didn’t line up correctly before feeding it into the model. This often happens when there is an issue with indexing, leading the system to see the data as empty when it isn’t.
To avoid this error, validate your indices and ensure your data is aligned correctly. Here’s a boilerplate approach you can follow:
import pandas as pd
# assuming df is your DataFrame and 'label' is your target column
X = df.drop('label', axis=1)
y = df['label']
print(f'Shape of X: {X.shape}')
print(f'Shape of y: {y.shape}')
This piece of code will print the shape of your feature set (`X`) and targets (`y`). Make sure these make sense before passing `X` and `y` to your machine-learning function.
2. Empty DataFrame/Series:
Perhaps you’ve implemented some row-wise filtering or transformation right before calling your machine-learning function? These operations can sometimes result in an empty DataFrame or Series, leading to the dreaded ValueError.
To fix this, double check that your DataFrame or Series contains data right before your machine learning call:
print(df.head())
The head() method will show the first 5 rows of your DataFrame. If these are all NaNs or if the DataFrame is empty then you might have an issue.
3. Mishandling Missing Values:
Remember that SciKit-Learn models cannot handle missing (NaN) values natively. As a coder, you need to effectively manage missing data before attempting to feed it into a model.
This can be fixed by filling missing values with pandas:
df.fillna(value=0, inplace=True)
In this example, missing values are replaced by zero using the fillna() function.
4. Incorrectly Formed Arrays:
A very simple but surprisingly common cause of this ValueError is incorrectly formed arrays. Double-check your arrays: make sure they’re two-dimensional (as required by most sklearn functions), and verify their shapes. Also, check array lengths match throughout your code.
Whilst the error message “ValueError: n_samples=0” may initially seem cryptic, these solutions should provide you a robust blueprint for overcoming it, and allow you to further hone your data manipulation skills.There are a few potential reasons why you might be encountering the Valueerror: N_Samples=0 in your Python script or in the data you’re analyzing. Pinpointing errors like this one can feel like a bit of detective work, but honing your code debugging skills is a crucial part of evolving as a coder.
First off, let’s clarify what the ValueError: n_samples=0 message means. This error typically arises when an algorithm in Scikit-Learn, a popular machine learning library in Python, attempts to use some piece of data that contains no samples. In other words, it’s seeing an array with a length of 0. You’re trying to initiate a process with something non-existent.
So how do we go about fixing this? Consider the following possible causes and solutions:
• One common possibility is that there may be a problem with your preprocessing step. Perhaps you’ve used a selection criterion that excludes all your data, or maybe you have accidentally removed all data points during cleaning. Go back through your script and ensure that nothing in your preprocessing section could be inadvertently removing your dataframe contents.
#Example:
import pandas as pd
#Suppose df is the original data
df = pd.read_excel('data.xlsx')
#Suppose this preprocessing step was meant to remove only outliers
df = df[df['column'] > 10000]
In above snippet df[‘column’>10000] may remove all rows if none satisfy the condition. Hence, check your conditions on data.
• Another potential issue is that you might be referring to the wrong data structure at some point in your code – for instance, referencing an older version of a dataframe instead of the updated one.
#Example:
import pandas as pd
#Suppose df is the original data
df = pd.read_excel('data.xlsx')
df_cleaned = df.dropna()
# However in later code, mistakenly the old 'df' is used.
model = SomeModel()
model.fit(df)
# Make sure you're using the right version (in this case, df_cleaned)
model.fit(df_cleaned)
Remember, coding mistakes happen to the best of us, and they become less frequent with time and practice. If you’re unable to resolve your ValueError: n_samples=0 error considering these tips, don’t hesitate to reach out to relevant forums such as Stack Overflow or GitHub issues for additional help. After all, every error resolution will only serve to strengthen your coding skills further.