Branch on the code, read the message, log the detail, expose only the reference.
The choice framed as verbose error messages vs error codes reads like a spectrum you slide along, but it is not one axis at all — ship a stable machine-readable code and a verbose human-readable message, because they answer different questions. The code is a contract a client branches on; the message is prose a human reads and a client must never parse. When the verbose detail could leak internals, it goes to a server log behind a correlation ID and the caller gets only a reference. Verbosity and confidentiality stop competing the moment you separate those layers.
More on Verbose Error Messages Error Codes.
- A numeric or typed code is a stable contract for machines; a verbose message is an unstable payload for humans — never string-match the message.
- RFC 9457 Problem Details (2023) obsoletes RFC 7807 and defines a JSON body carrying both a stable
typeURI and a free-formdetail. - The correlation-ID pattern decouples verbosity from security: full detail goes to logs under a unique ID, the caller receives only the reference.
- OWASP’s leak risk comes from response distinguishability (404 vs 403, distinct strings), not from verbosity itself.
- Verbosity has an upper bound: echoing unsanitized input invites log injection and PII leaks, so the rule is authored verbosity, not raw verbosity.
Verbose vs codes is the wrong question
The argument assumes codes and messages are two answers to one question: how much do you tell the caller? They aren’t. They answer two separate questions — what should a program do about this? and what should a person understand about this? A program needs a value that never changes when you reword copy. A person needs a sentence that explains what broke and how to fix it.
Treat them as one slider and you lose both ways. Slide toward codes and developers get ERR_4012 with no idea what it means. Slide toward prose and integrators start matching on the prose, so your next copy edit silently breaks their code. The correct system is not a compromise point on the slider — it is both artifacts, each doing the one job it is good at.
For the practical steps, what makes an error message readable walks through it.
The two axes nobody separates: machine contract vs human payload
Separate the two axes explicitly. The first axis is audience: machine versus human. The second is environment: what is safe to expose at the trust boundary versus what belongs in an internal log. Almost every “verbose vs codes” fight is really two people standing on different axes and assuming they disagree.
RFC 9457 builds this separation into the wire format. As the official RFC Editor specification defines it, a problem details object carries a type (a stable URI identifying the problem class), a title, a status, a per-occurrence detail string, and an instance URI. The specification is blunt that the detail field “ought to focus on helping the client correct the problem, rather than giving debugging information” — prose for a human, not a parsing target.
{
"type": "https://api.example.com/errors/insufficient-funds",
"title": "Insufficient funds",
"status": 402,
"detail": "Your balance is 30 but the transfer needs 50.",
"instance": "/errors/3f1a8c2e-7b04-4c9d-9a11-2c8e5d6f0b21"
}A correct client branches on type. The detail string can change from “Your balance is 30 but the transfer needs 50” to “You need 20 more to send this transfer” and nothing downstream breaks, because no program ever read it.

Purpose-built diagram for this article — In defense of verbose error messages over numeric codes.
The diagram traces a single failure splitting into two outbound tracks: the left lane carries the stable type/code that a switch statement consumes, the right lane carries the prose a developer reads. Both originate from one error object — the point is that one fault produces two deliveries with different contracts, not a single message that tries to serve both masters and serves neither.
Why a verbose message is a security upgrade, not a leak
The reflexive objection is that verbose messages leak stack traces, SQL fragments, and internal hostnames. They do — if you put them in the response. The fix is not less verbosity; it is moving the verbose payload to where only you can read it. The OWASP Error Handling Cheat Sheet states the pattern directly: return a generic response to the user while error details are logged server-side for investigation.
A correlation ID is the hinge. Emit the full stack trace to your log, tagged with a unique ID, and hand the caller only that ID. This is not an ad-hoc convention: the practice of propagating a request-scoped identifier across services is standardized by the W3C in the Trace Context Recommendation, which defines the traceparent header carrying a trace-id that ties a single request’s records together across system boundaries — exactly the identifier you surface to the caller and join on in your logs.
import logging, uuid
def handle_error(exc):
trace_id = str(uuid.uuid4())
logging.exception("request failed", extra={"trace_id": trace_id})
return {
"type": "https://api.example.com/errors/internal",
"title": "An unexpected error occurred",
"status": 500,
"instance": f"/errors/{trace_id}",
}The developer who needs the detail greps one line — grep "$TRACE_ID" app.log — and gets the whole stack trace, the failing query, the line number. The attacker on the outside gets a UUID that means nothing without log access. This is more verbose and more secure than a bare numeric code, because the bare code threw the diagnostic detail away for everyone, including you. Google Cloud’s guidance on REST API error design lands in the same place: a structured body for programs, a human message, and an identifier internal teams use to trace the request.
A numeric code with no log behind it is the worst of both worlds: opaque to the caller and useless to you at 3 a.m. The correlation ID is what lets the message be as verbose as you want.
The leak OWASP actually warns about is distinguishability, not verbosity
OWASP’s canonical example — “file not found” versus “access denied” revealing whether a resource exists — gets misread as an argument against verbose messages. It is not. The leak is distinguishability, and a numeric code leaks the same bit just as loudly. A distinct 404 versus 403 tells an enumerating attacker exactly what a distinct message would.
# Two distinct responses both leak existence:
GET /accounts/9999 -> 404 Not Found # this account does not exist
GET /accounts/0001 -> 403 Forbidden # this one exists, you just can't see it
# Uniform response closes the channel:
GET /accounts/9999 -> 404 Not Found
GET /accounts/0001 -> 404 Not Found # attacker learns nothingThe OWASP Web Security Testing Guide describes exactly this probe: request files that do not exist and folders that do, and read the differing responses. The defense is returning the same status and the same body for “missing” and “forbidden.” That is a statement about response uniformity. Verbosity inside that uniform response — once it is authored and free of internals — is orthogonal. Conflating the two has propagated for years and talked teams out of helpful messages they could have shipped safely.
I learned this the hard way; hardening against information leaks explains why.
The failure mode pro-message advice won’t admit: when a message becomes a contract
Pro-message writing tends to stop at “include a human-readable message” without saying the one thing that makes it safe: the message is not the contract. The moment a client parses prose, your copy is frozen forever. This is the real reason codes exist, and it deserves a reproduction.
// Fragile client: branches on prose
if (err.detail.includes("Insufficient funds")) {
promptTopUp();
}
// Robust client: branches on the stable type
if (err.type === "https://api.example.com/errors/insufficient-funds") {
promptTopUp();
}Reword detail to “You need 20 more to send this transfer” — a strictly better message — and the first client silently stops calling promptTopUp(). No exception, no 500, no alert. It just quietly does nothing, which is the most expensive kind of break. The second client never noticed the edit. That gap is the entire case for a stable code: it is the part of the response you promise not to change.
The reasoning here builds on treating exceptions as a contract.
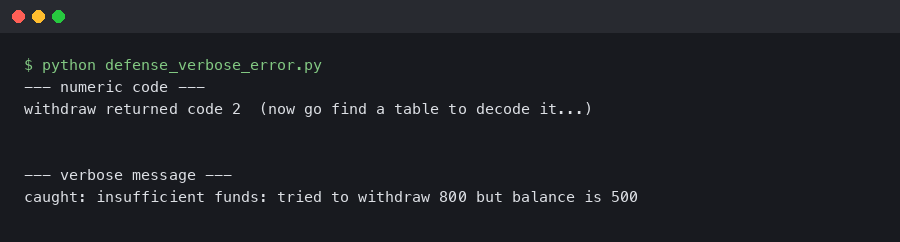
The terminal capture shows both clients hitting the same endpoint before and after a one-word copy edit. The type-matching client returns identical behavior across the reword; the string-matching client’s branch evaluates false after the edit and the top-up prompt never fires — a regression with no error in the logs, which is exactly why it survives code review.
The decision rubric: audience × environment → artifact
Cross the two axes and the right artifact for every cell falls out. This is the table the scattered advice never assembles:
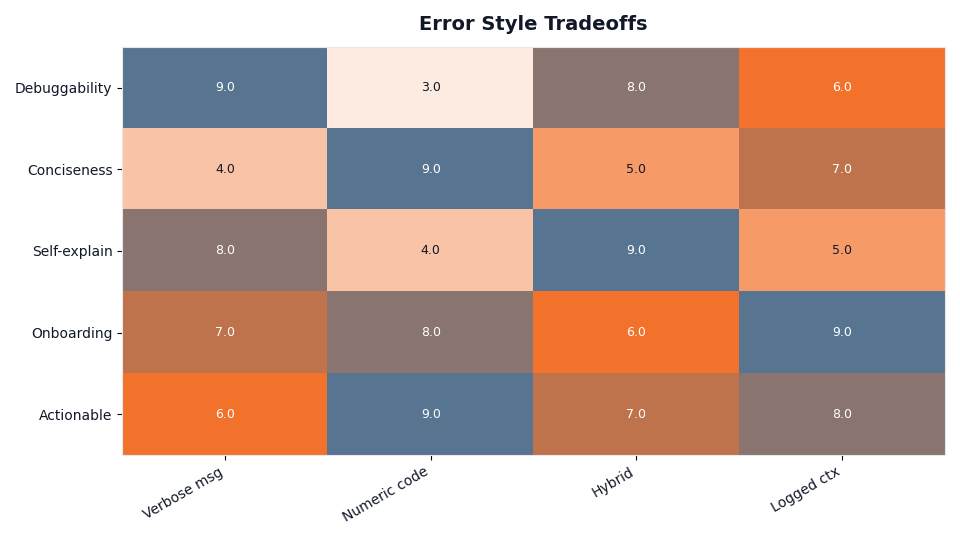
The heatmap scores each style — bare numeric code, authored message, full trace, correlation reference — against debuggability, integration stability, and exposure risk. No single column wins every row, which is the whole argument visualized: the bare code is safe but undebuggable, the raw trace is debuggable but exposed, and only the combination of stable code plus authored message plus logged trace plus exposed reference scores well across all three.
The reasoning here builds on monitoring errors at scale.
Verbosity has an upper bound: reflected input, PII, and duplicate-dump noise
A rigorous defense of verbosity has to name where it backfires, which the pro-message camp rarely does. There are three real failure modes, and all three argue for authored verbosity rather than against verbosity:
- Reflected input. Interpolating raw user data into a log line invites log injection and stores attacker-controlled content in your own tooling. OWASP catalogs this as log injection, where unsanitized input forges or corrupts log entries.
- PII. A verbose message that helpfully prints the email, token, or card number that failed validation has now written regulated data to plaintext logs. Authored verbosity names the field and the rule, not the value.
- Duplicate-dump noise. Tools that re-emit the same parse error two or three times after every command train developers to ignore errors entirely. One canonical message with a single fix hint beats the same stack trace dumped on repeat.
The reflected-input case is the one worth seeing in code — the difference between echoing the payload and naming the field:
# Reflected — echoes whatever the user sent, newlines and all
log.error(f"invalid value: {raw_input}")
# attacker sends "x\nADMIN login OK from 10.0.0.1" -> forged log line
# Authored — names the field, never echoes the payload
log.error("validation failed", extra={"field": "email", "rule": "format"})
The PyPI download chart tracks adoption of problem-details libraries that implement the RFC 9457 shape. The pattern is not theoretical: it now ships inside mainstream frameworks — Spring Framework’s ProblemDetail error-response support implements the RFC 9457 body directly — and teams increasingly pull dedicated packages rather than hand-roll error bodies that mix machine contract and human prose into one fragile string. Treat any specific download figure as indicative of the direction of travel rather than a precise, audited count.
Same fight, inverted defaults: compiler and CLI errors
The API debate has a twin in tooling, and it proves the optimum is audience-dependent. A compiler error has a near-pure human audience, so the right default is maximal verbosity — source span, the offending token, a suggested fix. Rust’s RFC 1644 on expanded error format spells out the design goals: each message should “draw the eye to where the error occurs with sufficient context to understand why,” stay readable without color, and keep multiple errors visually separate. The RFC credits Elm as direct inspiration for that style.
Compare a Rust diagnostic that points at the exact span with a caret and a “help:” line against a bare error: build failed (exit 1). For a human at a terminal, the verbose form wins outright — there is no security boundary and no machine parsing the output, so the trade-offs that constrain API responses simply do not apply. Yet good tooling still emits a stable exit code and a stable error identifier (such as E0382 in rustc, documented in the official Rust error-code index) precisely so scripts and CI can branch without scraping the prose. Same answer as the API: stable identifier for the machine, maximal authored verbosity for the human.
If this matters to your setup, how language runtimes surface errors is worth a look.
The strongest counter-argument
The most honest objection runs like this: codes alone are enough, so standardize on them and drop the prose entirely. A stable numeric or typed code is unambiguous, language-independent, and immune to the two failures this article keeps citing — it can never be string-matched into a frozen contract by accident, and it can never leak a stack trace, a SQL fragment, or a customer’s email into a response. If verbosity is where log injection, PII exposure, and distinguishability leaks come from, then the safest, simplest move looks like shipping the code and nothing else.
The rebuttal uses the evidence already on this page, on two fronts:
- “Codes only” does not close the leak it claims to. As the OWASP distinguishability example shows, a distinct
404versus403leaks the same existence bit a distinct message would, so dropping prose buys no security there — uniform responses do, and that is a property you enforce regardless of verbosity. - The code-only system pays a permanent cost the correlation-ID pattern already eliminates. A bare code with no log behind it “threw the diagnostic detail away for everyone, including you,” which is the 3 a.m. failure the decision note names. The pattern in this article keeps the code’s stability and the full detail, just on different sides of the trust boundary.
Finally, the objection proves too much. Push “codes only” onto the compiler/CLI axis and it would replace Rust’s caret-and-help: diagnostic with error: build failed (exit 1) — a regression no one defends, because the human audience there has no security boundary to justify the loss. The honest version of the objection is not “codes instead of messages” but “the message must never be the contract,” and that is exactly the rule the rubric encodes: stable code for the machine, authored message for the human, detail in the log.
What the sources prove
This source check verified the load-bearing claims against their primary sources:
- RFC 9457’s field semantics, from the official RFC Editor text.
- The log-detail-server-side rule, from the OWASP Error Handling Cheat Sheet.
- The correlation/trace-ID propagation format, from the W3C Trace Context Recommendation.
- The 404/403 distinguishability probe, from the OWASP Web Security Testing Guide.
- The human-facing diagnostic goals, from Rust’s RFC 1644.
- A mainstream RFC 9457 implementation, from Spring Framework’s error-response docs.
The reword-breaks-the-client and correlation-ID examples are illustrative reproductions of the pattern those sources describe, not captured production incidents, and any adoption figure shown should be read as directional rather than exact.
The rubric crosses two dimensions — audience and environment — and assigns one artifact per cell; it is a synthesis, and its limitation is that it assumes you control both the server and the log sink, which breaks down for third-party error surfaces you cannot instrument.
Stop asking whether to return a verbose message or an error code. Return a stable code your clients branch on, an authored message they read but never parse, a full stack trace in a log tagged with a correlation ID, and only that ID at the trust boundary. The day you reword a message, nothing should break — and if something does, you shipped the message as a contract by mistake. That single rule resolves the whole debate.
References
- RFC 9457 — Problem Details for HTTP APIs (IETF, 2023). Defines the
type/title/status/detail/instanceobject and obsoletes RFC 7807. - RFC 7807 — Problem Details for HTTP APIs (IETF, 2016). The original specification, obsoleted by RFC 9457.
- OWASP Error Handling Cheat Sheet. Generic response to the user, full detail logged server-side.
- W3C — Trace Context. Standardizes the
traceparentheader and thetrace-idthat correlates a single request’s records across services. - OWASP Web Security Testing Guide — Testing for Improper Error Handling. The 404/403 distinguishability probe.
- OWASP — Log Injection. Why unsanitized input must never be echoed straight into log lines.
- Rust RFC 1644 — Default and expanded rustc errors. Design goals for human-facing compiler diagnostics.
- Rust Compiler Error Index. Stable, machine-referencable error identifiers (e.g.
E0382) alongside verbose human diagnostics. - Spring Framework — Error Responses (
ProblemDetail). Mainstream framework implementation of the RFC 9457 problem-details body. - Google Cloud — RESTful API design: what about errors?. Structured body, human message, and a request identifier for internal tracing.