The adoption of Kubernetes has revolutionized how we deploy and manage applications, offering unprecedented scalability, resilience, and portability. However, this power comes with a new layer of complexity. When things go wrong, the distributed and ephemeral nature of containerized environments can turn a simple bug into a daunting mystery. Traditional debugging techniques often fall short, leaving engineers searching for a needle in a haystack of containers, services, and network policies. The key to taming this complexity is a systematic approach to Kubernetes Debugging.
This guide provides a comprehensive roadmap for navigating the challenges of debugging applications on Kubernetes. We will move from foundational pod-level diagnostics to advanced network traffic analysis and performance profiling. Whether you’re dealing with a pod stuck in a crash loop, a mysterious service connectivity issue, or a “one-in-a-million” production failure, this article will equip you with the practical skills, tools, and Debugging Best Practices to diagnose and resolve issues efficiently. By mastering these techniques, you can transform debugging from a source of frustration into a streamlined, effective process, ensuring the stability and reliability of your microservices architecture.
The Foundation: Debugging Pods and Containers
In Kubernetes, the Pod is the smallest and most fundamental deployable unit. Understanding its lifecycle and how to inspect its state is the first and most critical step in any debugging process. When an application fails, the problem often originates within the pod itself, making it the primary focus of your initial investigation.
The Pod Lifecycle: A First Look
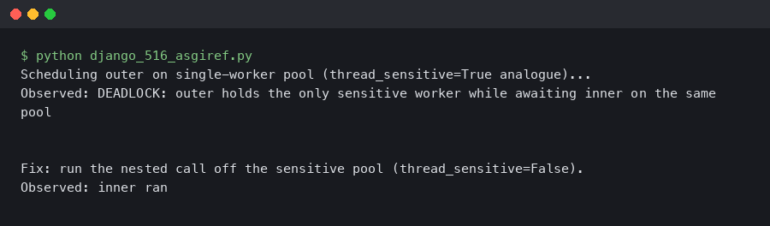
A Pod progresses through several phases in its lifecycle, such as Pending, Running, Succeeded, or Failed. A common and frustrating state is CrashLoopBackOff, which indicates a container is starting, crashing, and being restarted by Kubernetes repeatedly. The first command to run is always kubectl get pods to get a high-level overview. To dig deeper, kubectl describe pod is your best friend. It provides a wealth of information, including the pod’s current status, recent events, volume mounts, and container restart counts.
The Events section at the bottom of the output is often the most valuable, as it shows what the Kubernetes scheduler and kubelet are doing with your pod. Look for messages like “Failed to pull image,” “Back-off restarting failed container,” or resource-related errors.
# First, get the status of your pods
kubectl get pods
# Pick a failing pod (e.g., one in CrashLoopBackOff or Pending state)
# and describe it to get detailed information and events.
kubectl describe pod my-failing-app-pod-7f5b9cd4c-abcde
# --- Sample Output Snippet ---
# Name: my-failing-app-pod-7f5b9cd4c-abcde
# Namespace: default
# ...
# Status: Running
# ...
# Containers:
# my-app:
# ...
# State: Waiting
# Reason: CrashLoopBackOff
# Last State: Terminated
# Reason: Error
# Exit Code: 1
# Started: ...
# Finished: ...
# Ready: False
# Restart Count: 5
# ...
# Events:
# Type Reason Age From Message
# ---- ------ ---- ---- -------
# Normal Scheduled 2m33s default-scheduler Successfully assigned default/my-failing-app-pod to gke-node-1
# Normal Pulled 85s (x3 over 2m) kubelet Container image "myapp:1.0" already present on machine
# Normal Created 85s (x3 over 2m) kubelet Created container my-app
# Normal Started 84s (x3 over 2m) kubelet Started container my-app
# Warning BackOff 53s (x4 over 90s) kubelet Back-off restarting failed containerDiving into Logs
Once you’ve identified a problematic pod, the next step is to inspect its logs. For Logging and Debugging, nothing is more fundamental than the output of your application. The kubectl logs command streams the standard output and standard error from a container.
However, in a microservices architecture, you often need to correlate logs from multiple pods belonging to the same service. Tailing logs from each pod individually is inefficient. This is where tools like Stern shine. Stern allows you to tail logs from multiple pods and containers at once, color-coding the output for easy readability. This is invaluable for tracking a request as it flows through different services.
# Get logs from a specific pod
kubectl logs my-failing-app-pod-7f5b9cd4c-abcde
# Follow the logs in real-time
kubectl logs -f my-failing-app-pod-7f5b9cd4c-abcde
# Use Stern to tail logs from all pods managed by a deployment
# This command will find all pods with the label "app=my-api"
stern app=my-apiInteractive Debugging with kubectl exec
Sometimes, logs aren’t enough. You may need to inspect the running environment inside a container. The kubectl exec command lets you run a command inside a running container, most commonly to open an interactive shell. This form of Remote Debugging is perfect for checking environment variables, testing network connectivity to other services from within the pod, or examining the local filesystem.

# Get an interactive bash shell inside a running container
kubectl exec -it my-running-app-pod-12345-xyz -- /bin/bash
# Once inside the container, you can use standard Linux tools
# Check environment variables
printenv | grep API_KEY
# Test connectivity to another service
curl http://my-database-service:5432
# Check disk space
df -hBeyond the Pod: Network and Service Debugging
When your pod is running correctly but still can’t communicate with other services, the problem likely lies in the Kubernetes networking layer. Network Debugging in Kubernetes involves understanding how Services, DNS, and Network Policies interact to control traffic flow.
Untangling Service Discovery
In Kubernetes, you rarely connect to pods directly. Instead, you connect to a Service, which provides a stable IP address and DNS name that load-balances traffic to a set of backend pods. A common source of errors is a mismatch between the Service’s selector and the labels on your pods.
To debug this, start by inspecting the Service and its corresponding Endpoints object. The Endpoints object lists all the pod IPs that are currently matched by the Service’s selector. If the Endpoints object is empty, your selector is incorrect, or none of the matching pods are in a `Ready` state.
You can also test DNS resolution from within the cluster. Launch a temporary debug pod and use tools like `nslookup` or `dig` to verify that your Service’s DNS name (e.g., `my-service.my-namespace.svc.cluster.local`) resolves to the correct ClusterIP.
Network Policy and Connectivity Issues
Network Policies act as a firewall within the cluster, controlling which pods can communicate with each other. A misconfigured or overly restrictive Network Policy is a frequent cause of silent connection failures. If you suspect a Network Policy is blocking traffic, you can temporarily remove it to confirm your hypothesis. A more systematic approach is to use a debug pod to test connectivity. Tools like `nicolaka/netshoot` are Docker images packed with a comprehensive set of networking tools, perfect for this purpose.
# Launch a temporary pod with networking tools to debug from inside the cluster
# The --rm flag ensures the pod is deleted when you exit the shell
kubectl run net-debug --image=nicolaka/netshoot --rm -it -- /bin/bash
# --- Inside the net-debug pod ---
# Test DNS resolution for a service in the 'database' namespace
nslookup postgres-service.database
# Try to connect to a service's port
curl -v my-api-service.default.svc.cluster.local:8080
# Check if a Network Policy is blocking traffic (this will likely time out if blocked)
# The -z flag tells nmap to do a port scan without sending any data
nmap -p 80 -z my-web-server.defaultAdvanced Techniques for Elusive Failures
Some of the most challenging bugs are those that occur intermittently or only under specific conditions in a live environment. For this kind of Production Debugging, you need more advanced tools that provide deep insights without disrupting the running system.
Ephemeral Debug Containers
What if your production container image is minimal and lacks debugging tools like `curl` or `tcpdump`? In the past, you would have to rebuild the image and redeploy, which is slow and risky. The modern solution is the ephemeral debug container, accessible via kubectl debug. This powerful feature allows you to attach a new container, complete with all your favorite Debug Tools, to a running pod. This new container can share the same process namespace and network stack as the application container, giving you a perfect environment for live, in-place System Debugging without altering the original pod spec.
# Attach a new container named 'debugger' with the 'busybox' image to 'my-pod'
# This creates a copy of the pod with the new container added.
kubectl debug -it my-pod --image=busybox --share-processes --copy-to=my-pod-debug
# --- Inside the debugger container ---
# You can now see and interact with processes from the main app container
ps aux
# You can also inspect the shared network stack
netstat -tulnResource Constraints: Memory and CPU Debugging

Applications can fail due to resource exhaustion. A container exceeding its memory limit will be terminated by the kubelet with an “OOMKilled” (Out of Memory) error. A container that constantly uses all its CPU allocation will be throttled, leading to high latency and poor performance. The kubectl describe pod command will show if a container was terminated due to OOMKilled. For real-time usage, kubectl top pod provides a quick snapshot of CPU and memory consumption.
For deeper Memory Debugging and Debug Performance analysis, you need to use Profiling Tools and Performance Monitoring solutions. Integrating your cluster with a monitoring stack like Prometheus and Grafana is essential. This allows you to visualize resource usage over time, set up alerts for high consumption, and correlate resource spikes with other events in the system.
Distributed Tracing for Microservices Debugging
In a complex system of microservices, a single user request can trigger a chain of calls across dozens of services. When that request fails or is slow, logs from a single service only tell part of the story. This is where distributed tracing becomes indispensable for Microservices Debugging. By instrumenting your code using standards like OpenTelemetry, you can generate traces that track a request’s entire journey. Tools like Jaeger or Zipkin then visualize these traces, showing you the latency of each step and helping you pinpoint the exact service that is causing the bottleneck or error. This level of visibility is crucial for effective API Debugging in a distributed environment.
Best Practices and Proactive Debugging
The most effective debugging strategy is to prevent bugs from reaching production in the first place. This involves building observability into your systems from day one and adopting a proactive mindset.
The Three Pillars of Observability
A truly observable system is built on three pillars: Logs, Metrics, and Traces.
- Logs: Detailed, timestamped records of discrete events. They are great for understanding what happened in a specific component at a specific time.
- Metrics: Aggregated numerical data measured over time, such as CPU usage, request latency, or error rates. They are ideal for monitoring overall system health and identifying trends (e.g., using Prometheus).
- Traces: A representation of the entire lifecycle of a request as it moves through the system. They are essential for understanding component interactions and debugging performance issues in a microservices architecture.
A robust Error Monitoring platform can consume data from all three pillars to provide a holistic view of your application’s health.

Implementing Health Checks
Kubernetes uses health checks (probes) to determine if a container is healthy and ready to receive traffic.
- Liveness Probes: Check if your application is still running. If the probe fails, Kubernetes will restart the container. Use this to recover from deadlocks.
- Readiness Probes: Check if your application is ready to serve traffic. If it fails, Kubernetes will remove the pod’s IP from the Service Endpoints until it passes again. Use this for initial startup tasks or temporary unavailability.
- Startup Probes: Protect slow-starting applications by disabling liveness and readiness checks until the application has fully initialized.
Properly configured probes are a cornerstone of building self-healing applications on Kubernetes.
Automation and Tooling
Integrate debugging and analysis into your development lifecycle. Use Static Analysis tools in your CI/CD Debugging pipeline to catch potential issues before deployment. Leverage cluster management tools like k9s or Lens, which provide powerful terminal-based UIs for navigating Kubernetes resources, making it much faster to inspect logs, describe pods, and exec into containers. Automating your Testing and Debugging processes reduces manual effort and helps ensure consistency.
Conclusion
Kubernetes Debugging is a multifaceted discipline that requires a different mindset than traditional application debugging. It’s a journey that starts with the fundamental building block—the Pod—and expands outward to encompass the intricate web of networking, service discovery, and resource management that defines a cluster.
By mastering a layered approach—starting with kubectl describe and kubectl logs, moving to network diagnostics with debug containers, and leveraging advanced tools like ephemeral containers and distributed tracing—you can systematically dissect any problem. The ultimate goal is to move beyond reactive bug fixing. By embracing the principles of observability and integrating robust health checks and automated tooling into your workflow, you can build resilient, self-healing systems that are easier to manage, scale, and, most importantly, debug. Start implementing these strategies today to transform your Kubernetes troubleshooting experience from a daunting challenge into a core engineering strength.