It was 2:30 AM on a Tuesday. I was staring at a traceback that spanned three monitors, and my AI assistant—which I pay a monthly subscription for, mind you—had just suggested the exact same fix I had already tried (and rejected) twenty minutes prior.
You know the feeling. You paste the error. The AI suggests a patch. You run it. It breaks something else. You paste the new error. The AI apologizes and suggests… the code you started with.
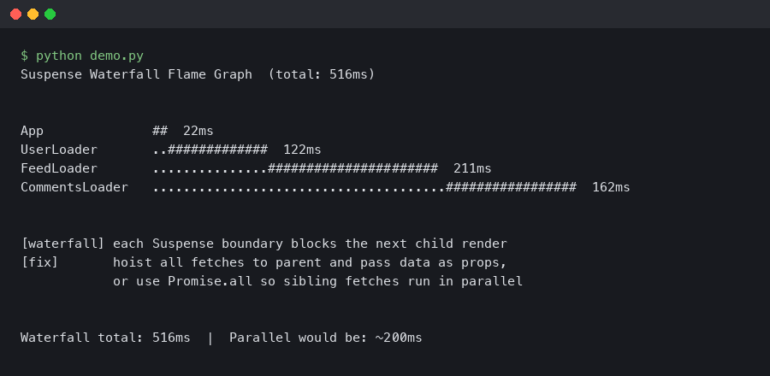
It’s the “Groundhog Day” loop of AI debugging. And when your codebase hits 1 million lines, it stops being funny and starts being a liability. I realized recently that the problem isn’t the model’s intelligence. It’s not that the AI is stupid. It’s that it has no working memory.
The Context Trap
We’ve been sold a lie about context windows. “200k tokens! 1 million tokens!” Great. But have you ever tried to shove an entire monolithic repo into a prompt? The model doesn’t just get slow; it gets confused. It starts hallucinating imports from files that don’t exist. It forgets that utils.py was refactored three months ago.
The issue is statelessness.
Every time you start a new session or the context slides too far, the AI resets. It doesn’t know that we already established that the database connection pool is the bottleneck, not the query itself. It approaches every prompt like it’s the first day of school.
I got tired of re-explaining my architecture to a machine. So, I stopped treating the AI like a chatbot and started treating it like a junior dev who needs a written log.
Externalizing Working Memory
If the AI can’t remember, we have to remember for it. I started experimenting with a concept I call “Persistent Session State.” Instead of relying on the chat history (which gets truncated or lost), I maintain a dedicated memory file in the root of my repo.

Think of it as a scratchpad that persists between CLI calls. When I’m debugging a gnarly race condition, I don’t just ask for a fix. I force the AI to read and update this file.
Here is the dirty Python script I threw together to manage this. It wraps my API calls and injects a _debug_context.md file into the system prompt automatically.
import os
import sys
from pathlib import Path
# The file where we store the "brain" of the current debugging session
MEMORY_FILE = Path(".ai_memory.md")
def load_memory():
if not MEMORY_FILE.exists():
return "NO PREVIOUS CONTEXT. STARTING FRESH."
return MEMORY_FILE.read_text()
def update_memory(new_insight):
# Append new findings to the memory file
with open(MEMORY_FILE, "a") as f:
f.write(f"\n- {new_insight}")
def build_prompt(user_query):
context = load_memory()
# This is the magic. We force the AI to acknowledge what it already knows.
system_instruction = f"""
You are an expert debugger.
CRITICAL: Read the following session history before answering.
Do NOT suggest solutions listed as 'FAILED' in the history.
=== CURRENT DEBUGGING STATE ===
{context}
===============================
"""
return f"{system_instruction}\n\nUser: {user_query}"
# Mocking the actual API call for this example
if __name__ == "__main__":
query = sys.argv[1] if len(sys.argv) > 1 else "What's wrong?"
print(f"Sending prompt with {len(load_memory())} bytes of context...")
# client.messages.create(...)
This looks primitive. It is. But it works.
Why This Changes the Game (Sorry, I Had To)
Actually, forget the hype words. Let’s talk about what actually happens when you use this.
Last week I was refactoring a legacy authentication module. Usually, this is a nightmare. The AI suggests importing AuthLib, realizes AuthLib isn’t installed, suggests pip install authlib, realizes I’m in a restricted environment, and we loop forever.
With the memory file, the flow looked like this:
- Attempt 1: AI suggests
AuthLib. I run it. It fails. - Memory Update: I (or the script) write to memory: “Tried AuthLib. Failed. Environment restricted. Do not suggest external packages.”
- Attempt 2: AI reads memory. Sees the restriction. Suggests a native Python implementation using
hmac.
That second step? That’s the difference between a 5-minute fix and a 2-hour headache. The AI stops guessing and starts deducing.
The “Hallucinated Import” Problem
One specific annoyance this solves is the hallucinated import. In massive codebases (I’m talking 1M+ lines), you inevitably have internal libraries with generic names like common.utils or core.services.

Standard LLMs guess what’s in those files based on the name. They assume common.utils has a timestamp_to_string function because, well, it should. But it doesn’t. Yours is called ts_convert because the guy who wrote it in 2019 was saving keystrokes.
By keeping a running map of “verified exports” in the memory file, the AI stops making things up. I essentially force it to double-check its own homework against the session log.
Automating the “I Tried That”
The real power move is automating the rejection. I’ve started piping my terminal errors directly into the memory file with a tag: [FAILED ATTEMPT].
So when I run a test and it explodes, I don’t just copy-paste the error to the chat. I append it to the context. The next time I prompt the AI, it sees:
[HISTORY]
1. User tried patching user_service.py with patch A.
2. Result: TypeError in line 45.
3. Constraint: Cannot change function signature of get_user.
Now the AI can’t suggest Patch A again. It physically (well, digitally) sees that path is blocked. It forces lateral thinking.

The Future is Stateful
We are moving away from “chatting” with code. Chat is a terrible interface for engineering because engineering is cumulative. You build on previous states. Chat implies ephemeral conversation.
By the end of 2026, I doubt we’ll be manually managing these context files. The tools will do it for us. We’re already seeing the early signs of “agentic memory” in open source projects—tools that create a hidden .sqlite database or JSON store for every project, tracking what the AI has learned about your specific spaghetti code.
But until those tools are standard in every IDE, you have to build the guardrails yourself.
Stop letting your AI start from zero every time you hit Enter. Give it a notebook. Force it to write down what failed. It’s the only way to keep your sanity when the line count adds another comma.