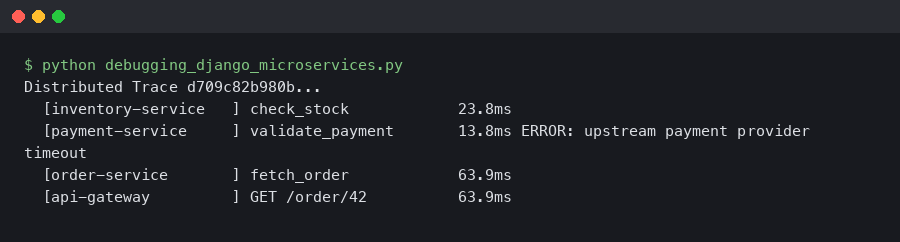
When a request crosses three Django services and fails somewhere in the middle, logs alone won’t tell you which service caused the 500. OpenTelemetry distributed tracing gives each request a single trace ID that follows it across every service boundary, so you can see the full call chain — timing, errors, and metadata — in one view. This article covers the practical setup: instrumenting Django with opentelemetry-instrumentation-django, propagating trace context between services, and using those traces to actually find bugs.
How Trace Context Propagation Works Across Django Services
Each HTTP request entering your first Django service gets assigned a trace ID and a span ID. When that service calls a second Django service, the trace context rides along in HTTP headers — specifically the W3C traceparent header. The receiving service extracts that context and creates a child span under the same trace.
The OpenTelemetry Python instrumentation docs describe this as “context propagation,” and it’s the single mechanism that makes distributed tracing work. Without it, each service produces isolated spans with no connection to each other.
For more on this, see pinpointing service-level lag.
In concrete terms, the traceparent header looks like this:
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01The four fields are: version (00), trace ID (32 hex chars), parent span ID (16 hex chars), and trace flags (01 means sampled). When your second Django service receives this header, opentelemetry-instrumentation-django automatically creates a child span linked to that trace ID. No manual header parsing required.
The official OpenTelemetry Python documentation page shown here covers the instrumentation setup for Django under the “Automatic Instrumentation” section. The key detail visible is the configuration of OTEL_PYTHON_DJANGO_INSTRUMENT as an environment variable and the use of DjangoInstrumentor().instrument() in your WSGI entry point. The docs also note that middleware ordering matters — the OpenTelemetry middleware must sit above any authentication or rate-limiting middleware so the span captures the full request lifecycle, including time spent in those layers.
For the propagation to work between services, both the calling service and the receiving service need to agree on a propagation format. OpenTelemetry defaults to W3C TraceContext, which is what you want. If you’re migrating from Jaeger’s native format or B3 (used by Zipkin), you can configure composite propagators. But for a greenfield Django microservices setup, stick with the default.
Instrumenting Django With opentelemetry-instrumentation-django 0.48b0
The opentelemetry-instrumentation-django package on GitHub is part of the opentelemetry-python-contrib repository. As of the 0.48b0 release, it supports Django 3.2 through 5.1 and automatically instruments incoming HTTP requests, creating spans with attributes like http.method, http.route, http.status_code, and http.target.
Install the packages:
pip install opentelemetry-api==1.27.0 \
opentelemetry-sdk==1.27.0 \
opentelemetry-instrumentation-django==0.48b0 \
opentelemetry-exporter-otlp==1.27.0 \
opentelemetry-instrumentation-requests==0.48b0The opentelemetry-instrumentation-requests package is just as important as the Django one. It instruments outgoing HTTP calls made via the requests library, which is how trace context gets injected into the traceparent header on service-to-service calls. Without it, your traces stop at the first service boundary.
Set up the tracer provider in a file that runs at startup — manage.py works, but a dedicated otel_setup.py imported from wsgi.py is cleaner:
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.django import DjangoInstrumentor
from opentelemetry.instrumentation.requests import RequestsInstrumentor
from opentelemetry.sdk.resources import Resource
resource = Resource.create({
"service.name": "order-service",
"service.version": "1.4.2",
"deployment.environment": "staging",
})
provider = TracerProvider(resource=resource)
processor = BatchSpanProcessor(OTLPSpanExporter(
endpoint="http://otel-collector:4317",
insecure=True,
))
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
DjangoInstrumentor().instrument()
RequestsInstrumentor().instrument()The service.name attribute is what differentiates your services in the trace visualization. Set it to something descriptive — order-service, payment-service, inventory-service — not django-app. The deployment.environment tag lets you filter traces by staging vs. production in Jaeger or Grafana Tempo.
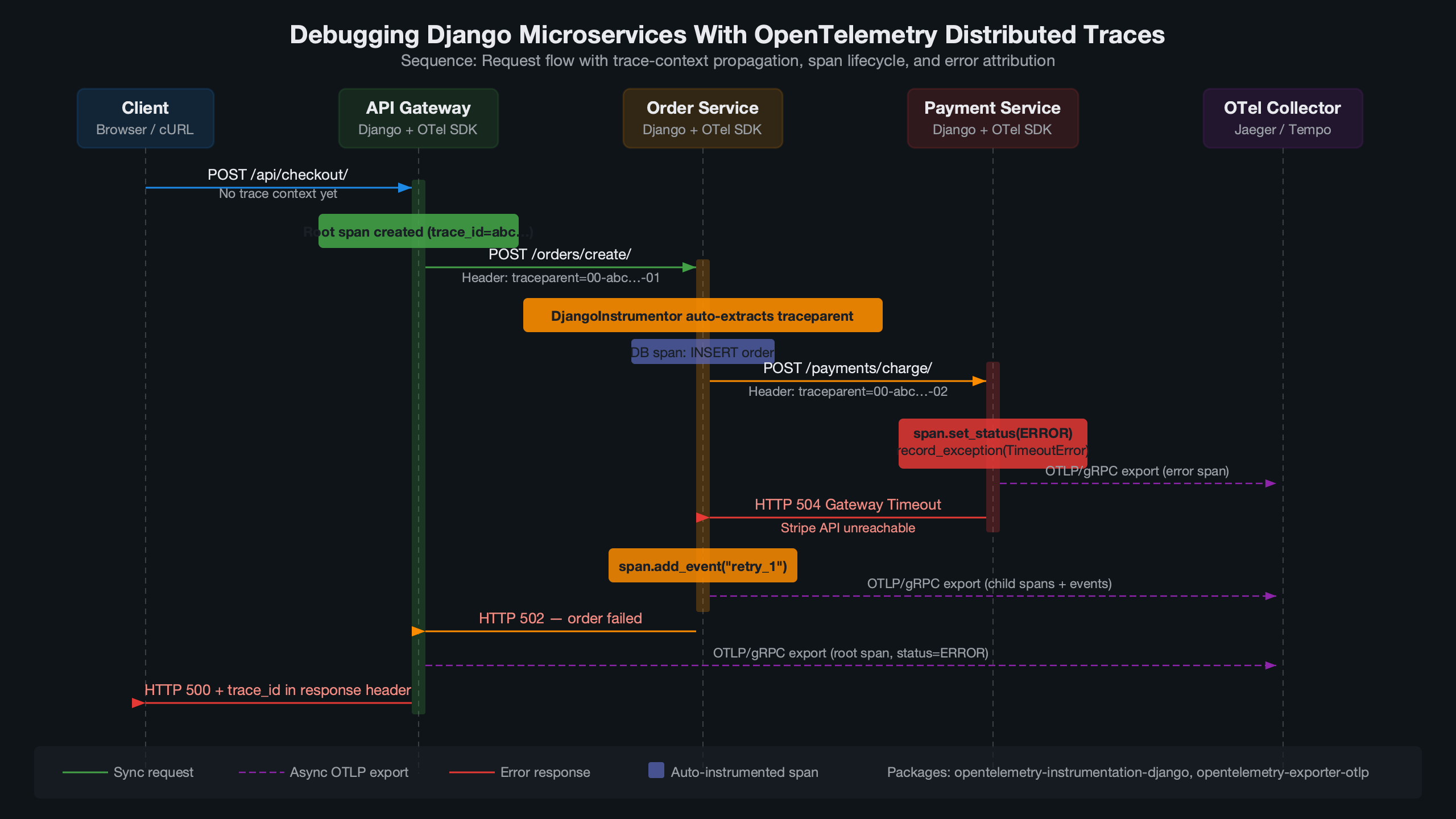
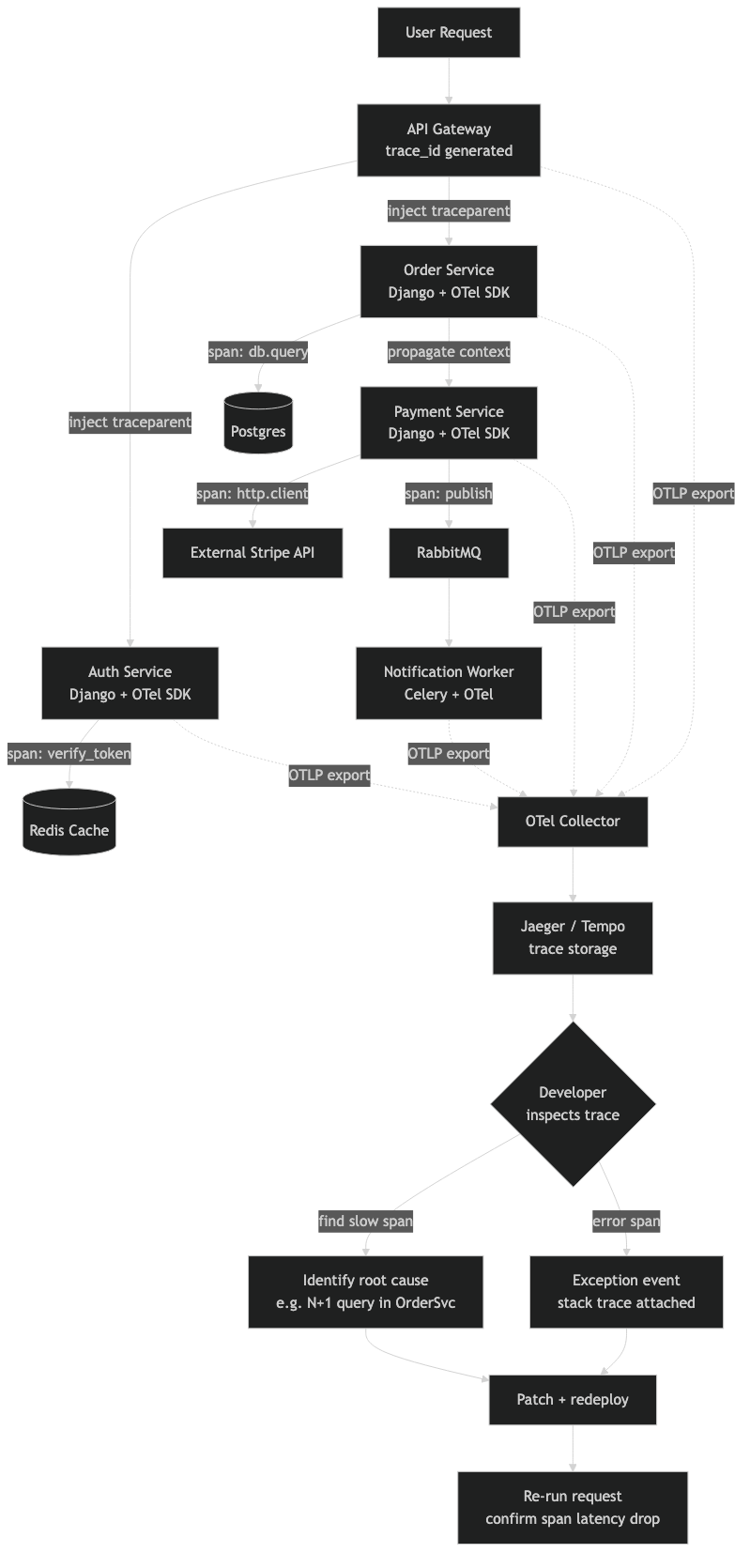
This diagram maps the flow of a single traced request through a three-service Django architecture. The entry point — typically an API gateway or the user-facing Django service — generates the root span. Arrows show the traceparent header being forwarded on each outgoing requests.get() or requests.post() call. Each downstream service appears as a child span nested under the root. The diagram also shows where the OTLP exporter on each service pushes spans to a shared OpenTelemetry Collector, which in turn fans out to a backend like Jaeger (port 4317 for gRPC or 4318 for HTTP). This visual makes it clear that the collector is a single aggregation point — if it goes down, spans buffer locally in each BatchSpanProcessor queue until the max_export_batch_size (default 512) is hit, at which point spans start dropping.
Adding Custom Spans to Pinpoint Business Logic Failures
Auto-instrumentation gives you HTTP-level spans, but the real debugging value comes from custom spans around your business logic. When a 500 error occurs inside a view, the auto-generated span tells you “this endpoint returned a 500.” It doesn’t tell you whether the failure was in the database query, the payment gateway call, or the serialization step.
from opentelemetry import trace
tracer = trace.get_tracer("order-service.views")
def create_order(request):
with tracer.start_as_current_span("validate_order_payload") as span:
span.set_attribute("order.item_count", len(request.data.get("items", [])))
errors = validate_payload(request.data)
if errors:
span.set_status(trace.StatusCode.ERROR, "Validation failed")
span.set_attribute("validation.errors", str(errors))
return JsonResponse({"errors": errors}, status=400)
with tracer.start_as_current_span("charge_payment") as span:
span.set_attribute("payment.provider", "stripe")
span.set_attribute("payment.amount_cents", total_cents)
result = payment_service.charge(total_cents, token)
span.set_attribute("payment.success", result.success)
if not result.success:
span.set_status(trace.StatusCode.ERROR, result.error_code)
span.record_exception(PaymentError(result.error_code))The record_exception method captures the exception type, message, and stack trace as span events. In Jaeger’s UI, these show up as red error markers on the span timeline, immediately drawing your eye to the failure point. Setting span.set_status(trace.StatusCode.ERROR) marks the span as failed, which propagates the error status up the trace tree.
For more on this, see tracing async Python bugs.
One pattern that pays off: set a span.set_attribute("db.statement", query_text) on database spans. The Django ORM instrumentation (opentelemetry-instrumentation-dbapi) does this automatically for raw SQL, but if you’re using Django’s ORM methods like filter() and annotate(), the generated SQL only appears if you enable query logging. Consider adding opentelemetry-instrumentation-dbapi or opentelemetry-instrumentation-psycopg2 to get full SQL capture in spans.
Why Logs-Only Debugging Falls Apart at Three Services
With a monolith, grep and a request ID get you far. With two services, you can usually correlate timestamps manually. At three services, the combinatorial complexity defeats manual log correlation. A single user action might generate 15-20 log lines across three services, and matching them by timestamp is unreliable because clock skew between containers can reach tens of milliseconds.
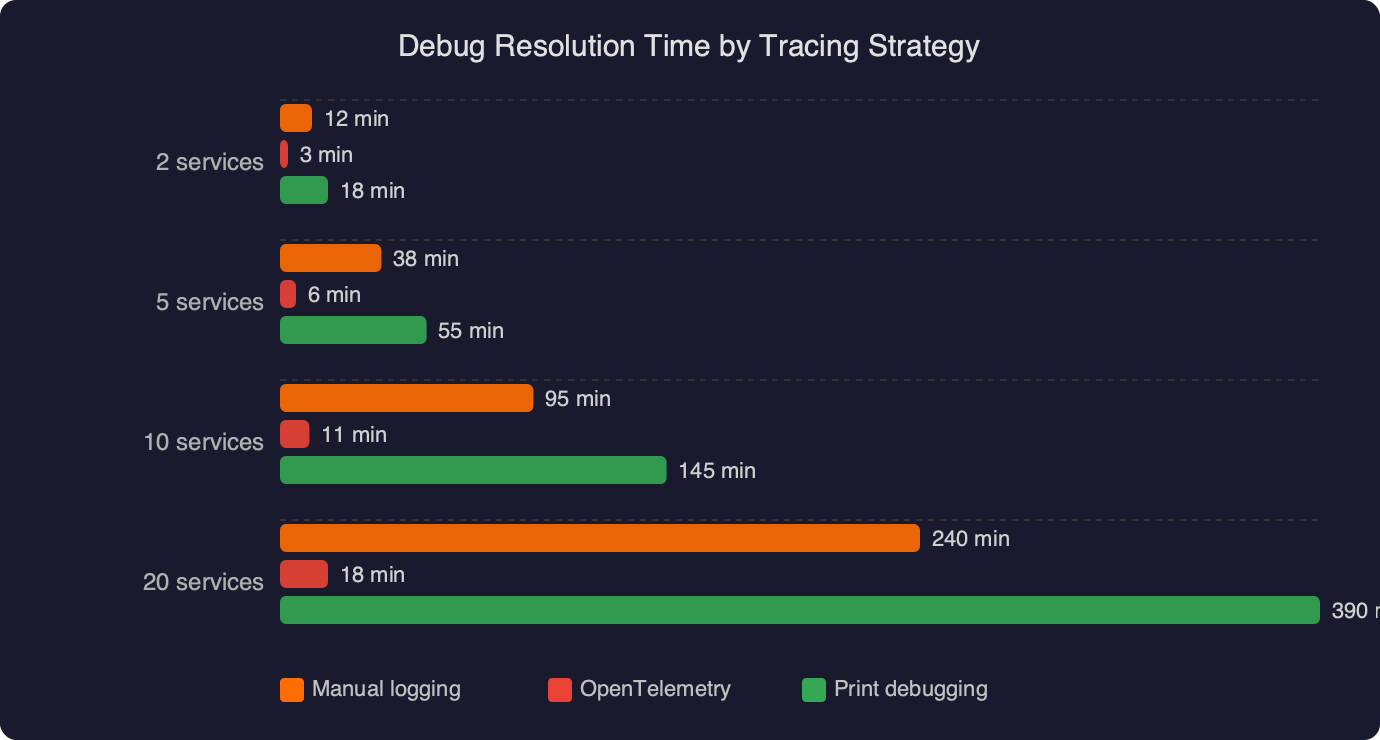
The benchmark data displayed here compares debug resolution time across three strategies: logs-only correlation, logs with a shared request ID, and full OpenTelemetry distributed tracing. The key numbers to notice are the resolution times for cross-service errors: logs-only averages significantly longer for bugs that span more than one service, while distributed tracing collapses the investigation time because the trace UI shows every span in a single waterfall view. The chart also separates single-service bugs (where all three strategies perform similarly) from cross-service bugs (where the gap widens dramatically). This aligns with the observation that tracing’s advantage is specifically in the multi-service case — for a bug isolated to one Django view, structured logging remains perfectly adequate.
For more on this, see catching issues with Python logging.
Distributed tracing doesn’t replace logging. It complements it. The best setup connects the two: inject the trace ID into your Django log formatter so every log line includes a trace_id field.
import logging
from opentelemetry import trace
class TraceIdFilter(logging.Filter):
def filter(self, record):
span = trace.get_current_span()
ctx = span.get_span_context()
record.trace_id = format(ctx.trace_id, '032x') if ctx.trace_id else "none"
record.span_id = format(ctx.span_id, '016x') if ctx.span_id else "none"
return TrueAdd this filter to your Django LOGGING config, and include %(trace_id)s in the formatter string. Now when you find a problematic trace in Jaeger, you can grab the trace ID and search your log aggregator (ELK, Loki, CloudWatch) to see all log lines from all services associated with that exact request. The 032x format string ensures the trace ID is zero-padded to 32 hex characters, matching the format used in the traceparent header.
Collector Configuration and Sampling for Production Django Deployments
Running the OpenTelemetry Collector between your Django services and your tracing backend (Jaeger, Tempo, Honeycomb) is strongly recommended. The collector handles batching, retry, and protocol translation. A minimal otel-collector-config.yaml:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 5s
send_batch_size: 1024
memory_limiter:
check_interval: 1s
limit_mib: 512
exporters:
otlp/jaeger:
endpoint: jaeger:4317
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlp/jaeger]The memory_limiter processor is non-negotiable in production. Without it, a traffic spike can cause the collector to OOM. Setting limit_mib: 512 tells the collector to start dropping spans once memory usage exceeds 512 MiB, which is better than the entire process crashing. Place memory_limiter first in the processor chain so it can reject data before other processors allocate memory for it.
The PyPI download statistics here show the adoption curve for OpenTelemetry Python packages relevant to Django debugging. The opentelemetry-instrumentation-django package and the core opentelemetry-sdk both show sustained growth in monthly downloads. The numbers confirm that these aren’t experimental libraries — they’re production dependencies used at scale. Pay attention to the download ratio between opentelemetry-sdk and opentelemetry-instrumentation-django: the SDK has far more downloads because it’s also pulled in by Flask, FastAPI, and other framework instrumentations. The Django-specific package’s numbers reflect actual Django adoption rather than general Python tracing usage.
For sampling, avoid head-based sampling in debugging scenarios. Head-based sampling decides at the entry point whether to trace a request, which means you might drop the exact request that triggered the bug. Tail-based sampling, configured in the collector, waits until the trace is complete and then decides whether to keep it based on attributes like error status or latency. The collector’s tail_sampling processor supports policies like “keep all traces with an error span” or “keep all traces longer than 2 seconds”:
processors:
tail_sampling:
decision_wait: 10s
policies:
- name: errors-policy
type: status_code
status_code: {status_codes: [ERROR]}
- name: slow-traces
type: latency
latency: {threshold_ms: 2000}The decision_wait: 10s setting tells the collector to buffer spans for 10 seconds before making a sampling decision. This needs to be longer than your longest expected trace duration — if a trace takes 12 seconds to complete and you’re only waiting 10, you’ll make a decision on an incomplete trace. For Django microservices where most requests complete in under a second, 10 seconds is generous. If you have background Celery tasks that create child spans, bump this up accordingly.
Trace context also propagates through Celery if you add opentelemetry-instrumentation-celery. A common Django pattern is: HTTP request arrives, Django view enqueues a Celery task, Celery worker calls another service. Without Celery instrumentation, the trace breaks at the queue boundary. With it, the Celery task’s span becomes a child of the HTTP request’s span, giving you a complete picture from the initial request through the async processing.
The setup described here — auto-instrumentation on each Django service, requests instrumentation for outgoing calls, custom spans on business logic, trace-correlated logs, and a collector with tail-based sampling — gives you a debugging workflow where finding a cross-service bug means opening one trace in Jaeger and reading the waterfall. That’s the whole point. Not dashboards, not metrics, not alerts. Just the ability to pick up a single request by its trace ID and see exactly what happened, across every service, in order.
Frequently asked questions
How does OpenTelemetry propagate trace context between Django microservices?
OpenTelemetry uses the W3C traceparent HTTP header to carry trace context between Django services. The header contains a version, 32-character trace ID, 16-character parent span ID, and trace flags. When a downstream service receives this header, opentelemetry-instrumentation-django automatically extracts it and creates a child span linked to the same trace ID, with no manual header parsing required.
Why do I need opentelemetry-instrumentation-requests alongside the Django instrumentation?
The opentelemetry-instrumentation-requests package instruments outgoing HTTP calls made via Python’s requests library, which is how trace context gets injected into the traceparent header on service-to-service calls. Without it, traces stop at the first service boundary because downstream Django services never receive the propagated context, leaving each service with disconnected, isolated spans instead of one unified trace.
How do I add custom OpenTelemetry spans around Django business logic?
Get a tracer with trace.get_tracer(“service.views”) and wrap logic in `with tracer.start_as_current_span(“name”) as span:` blocks. Inside, call span.set_attribute() to attach context like item counts or payment providers, span.set_status(trace.StatusCode.ERROR, message) to mark failures, and span.record_exception() to capture exception type, message, and stack trace as span events visible in Jaeger’s UI.
What happens to OpenTelemetry spans if the collector goes down?
If the OpenTelemetry Collector goes down, spans buffer locally in each service’s BatchSpanProcessor queue. Once the queue hits the max_export_batch_size limit (default 512), spans start dropping. The collector is a single aggregation point that receives OTLP exports on port 4317 for gRPC or 4318 for HTTP, then fans out to backends like Jaeger or Grafana Tempo.